What is Solr?
Solr builds on Lucene, an open source Java library that provides indexing and search technology, as well as spellchecking, hit highlighting and advanced analysis/tokenization capabilities.
- Launch Solr in SolrCloud Mode
solr-7.4.0:$ ./bin/solr start -e cloud
Notice that two instances of Solr have started on two nodes. Because we are starting in SolrCloud mode, and did not define any details about an external ZooKeeper cluster, Solr launches its own ZooKeeper and connects both nodes to it.
- Index the Techproducts Data
solr-7.4.0:$ bin/post -c techproducts example/exampledocs/*
- Search for a Single Term
curl "http://localhost:8983/solr/techproducts/select?q=foundation"
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":8,
"params":{
"q":"foundation"}},
"response":{"numFound":4,"start":0,"maxScore":2.7879646,"docs":[
{
"id":"0553293354",
"cat":["book"],
"name":"Foundation",
"price":7.99,
"price_c":"7.99,USD",
"inStock":true,
"author":"Isaac Asimov",
"author_s":"Isaac Asimov",
"series_t":"Foundation Novels",
"sequence_i":1,
"genre_s":"scifi",
"_version_":1574100232473411586,
"price_c____l_ns":799}]
}}
SolrCloud
You can scale up the capabilities of your application using SolrCloud to better distribute the data, and the processing of requests, across many servers. Multiple options can be mixed and matched depending on the scalability you need.
For example: “Sharding” is a scaling technique in which a collection is split into multiple logical pieces called “shards” in order to scale up the number of documents in a collection beyond what could physically fit on a single server. Incoming queries are distributed to every shard in the collection, which respond with merged results. Another technique available is to increase the “Replication Factor” of your collection, which allows you to add servers with additional copies of your collection to handle higher concurrent query load by spreading the requests around to multiple machines. Sharding and replication are not mutually exclusive, and together make Solr an extremely powerful and scalable platform.
Solr has support for writing and reading its index and transaction log files to the HDFS distributed filesystem. This does not use Hadoop MapReduce to process Solr data, rather it only uses the HDFS filesystem for index and transaction log file storage.
To set up a multi-node SolrCloud cluster on Amazon Web Services (AWS) EC2 instances for early development and design. You need to launch multiple AWS EC2 instances: 1. Create new Security Group; 2: Configure instances and launch. Then Install, configure and start Solr on newly launched EC2 instances.
JSON Formatted Index Updates
Index Handlers are Request Handlers designed to add, delete and update documents to the index. In addition to having plugins for importing rich documents using Tika or from structured data sources using the Data Import Handler, Solr natively supports indexing structured documents in XML, CSV and JSON.
curl -X POST -H 'Content-Type: application/json' 'http://localhost:8983/solr/my_collection/update' --data-binary '
{
"add": {
"doc": {
"id": "DOC1",
"my_field": 2.3,
"my_multivalued_field": [ "aaa", "bbb" ] // Can use an array for a multi-valued field
}
},
"add": {
"commitWithin": 5000, // Commit this document within 5 seconds
"overwrite": false, // Don’t check for existing documents with the same uniqueKey
"doc": {
"f1": "v1", // Can use repeated keys for a multi-valued field
"f1": "v2"
}
},
"commit": {},
"optimize": { "waitSearcher":false },
"delete": { "id":"ID" }, // Delete by ID (uniqueKey field)
"delete": { "query":"QUERY" } // Delete by Query
}'
Using SolrJ
SolrJ is an API that makes it easy for applications written in Java (or any language based on the JVM) to talk to Solr. SolrJ hides a lot of the details of connecting to Solr and allows your application to interact with Solr with simple high-level methods. SolrJ supports most Solr APIs, and is highly configurable.
All requests to Solr are sent by a SolrClient. SolrClient’s are the main workhorses at the core of SolrJ. They handle the work of connecting to and communicating with Solr, and are where most of the user configuration happens.
Requests are sent in the form of SolrRequests, and are returned as SolrResponses.
- Querying in SolrJ
SolrClient has a number of query() methods for fetching results from Solr. Each of these methods takes in a SolrParams,an object encapsulating arbitrary query-parameters. And each method outputs a QueryResponse, a wrapper which can be used to access the result documents and other related metadata.
final SolrClient client = getSolrClient();
final Map<String, String> queryParamMap = new HashMap<String, String>();
queryParamMap.put("q", "*:*");
queryParamMap.put("fl", "id, name");
queryParamMap.put("sort", "id asc");
MapSolrParams queryParams = new MapSolrParams(queryParamMap);
final QueryResponse response = client.query("techproducts", queryParams);
final SolrDocumentList documents = response.getResults();
print("Found " + documents.getNumFound() + " documents");
for(SolrDocument document : documents) {
final String id = (String) document.getFirstValue("id");
final String name = (String) document.getFirstValue("name");
print("id: " + id + "; name: " + name);
}
- Indexing in SolrJ
Indexing is also simple using SolrJ. Users build the documents they want to index as instances of SolrInputDocument, and provide them as arguments to one of the add() methods on SolrClient.
final SolrClient client = getSolrClient();
final SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", UUID.randomUUID().toString());
doc.addField("name", "Amazon Kindle Paperwhite");
final UpdateResponse updateResponse = client.add("techproducts", doc);
// Indexed documents must be committed
client.commit("techproducts");
- Java Object Binding
public static class TechProduct {
@Field public String id;
@Field public String name;
public TechProduct(String id, String name) {
this.id = id; this.name = name;
}
public TechProduct() {}
}
// Index
final SolrClient client = getSolrClient();
final TechProduct kindle = new TechProduct("kindle-id-4", "Amazon Kindle Paperwhite");
final UpdateResponse response = client.addBean("techproducts", kindle);
client.commit("techproducts");
// Search
final SolrClient client = getSolrClient();
final SolrQuery query = new SolrQuery("*:*");
query.addField("id");
query.addField("name");
query.setSort("id", ORDER.asc);
final QueryResponse response = client.query("techproducts", query);
final List<TechProduct> products = response.getBeans(TechProduct.class);
Apache Lucene
Lucene creates a big index (inverted index). The index contains word id, number of docs where the word is present, and the position of the word in those documents. So when you give a single word query it just searches the index (O(1) time complexity). Then the result is ranked using different algorithms. For multi-word query just take the intersection of the set of files where the words are present. Thus Lucene is very very fast.
Search has two principal stages: indexing and retrieval.
During indexing, each document is broken into words, and the list of documents containing each word is stored in a list called the “postings list”. The posting list for the word “My” is: My –> 1,5 And the posting list for the word “fudge” is: fudge –> 4,5 The index consists of all the posting lists for the words in the corpus. Indexing must be done before retrieval, and we can only retrieve documents that were indexed.
Retrieval is the process starting with a query and ending with a ranked list of documents. Say the query is [my fudge]. (The brackets denote the borders of the query). In order to find matches for the query, we break it into the individual words, and go to the posting lists. The full list of documents containing the keywords is [1,4,5]. Because document 5 contains both words and documents 1 and 4 contain just a single word from the query, a possible ranking is: 5, 1, 4 (document 5 appears first, then document 4, then document 1).
In general, indexing is a batch, preprocessing stage, and retrieval is a quick online stage, but there are exceptions.
Discretely Numerical
If you indexed your field with NumericField, you can efficiently search a particular range for that field using NumericRangeQuery. Under the hood, Lucene translates the requested range into the equivalent set of brackets in the indexed trie structure.
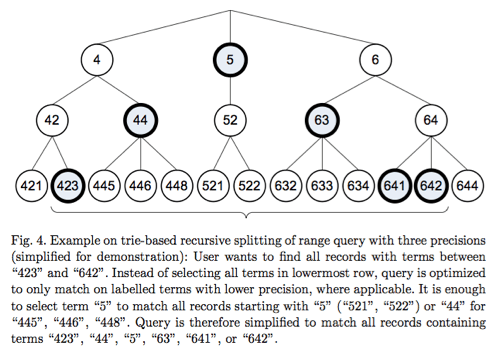
Mongo DB’s BTree Search

Lucene Scoring
Lucene scoring uses a combination of the Vector Space Model (VSM) of Information Retrieval and the Boolean model to determine how relevant a given Document is to a User’s query. In general, the idea behind the VSM is the more times a query term appears in a document relative to the number of times the term appears in all the documents in the collection, the more relevant that document is to the query. It uses the Boolean model to first narrow down the documents that need to be scored based on the use of boolean logic in the Query specification. Lucene also adds some capabilities and refinements onto this model to support boolean and fuzzy searching, but it essentially remains a VSM based system at the heart.
In Lucene, the objects we are scoring are Documents. A Document is a collection of Fields. Each Field has semantics about how it is created and stored (i.e. tokenized, untokenized, raw data, compressed, etc.) It is important to note that Lucene scoring works on Fields and then combines the results to return Documents. This is important because two Documents with the exact same content, but one having the content in two Fields and the other in one Field will return different scores for the same query due to length normalization (assuming the DefaultSimilarity on the Fields).
Lucene allows influencing search results by “boosting” in more than one level: document, field and query level. For each field of a document, all boosts of that field are multiplied. The result is multiplied by the boost of the document, and also multiplied by a “field length norm” value that represents the length of that field in that doc (so shorter fields are automatically boosted up).
So the tf-idf formula and the Similarity is great for understanding the basics of Lucene scoring, but what really drives Lucene scoring are the use and interactions between the Query classes, as created by each application in response to a user’s information need.
Once a Query has been created and submitted to the IndexSearcher, the scoring process begins. After some infrastructure setup, control finally passes to the Weight implementation and its Scorer instance. scoring is handled by the BooleanWeight2, a BooleanScorer2 is created by bringing together all of the Scorers from the sub-clauses of the BooleanQuery. When the BooleanScorer2 is asked to score it delegates its work to an internal Scorer based on the type of clauses in the Query. This internal Scorer essentially loops over the sub scorers and sums the scores provided by each scorer while factoring in the coord() score.
private int index(File indexDir, File dataDir, String suffix) throws Exception {
IndexWriter indexWriter = new IndexWriter( FSDirectory.open(indexDir), new SimpleAnalyzer(), true, IndexWriter.MaxFieldLength.LIMITED);
indexWriter.setUseCompoundFile(false);
indexDirectory(indexWriter, dataDir, suffix);
int numIndexed = indexWriter.maxDoc();
indexWriter.optimize();
indexWriter.close();
return numIndexed;
}
private void searchIndex(File indexDir, String queryStr, int maxHits) throws Exception {
Directory directory = FSDirectory.open(indexDir);
IndexSearcher searcher = new IndexSearcher(directory);
QueryParser parser = new QueryParser(Version.LUCENE_30, "contents", new SimpleAnalyzer());
Query query = parser.parse(queryStr);
TopDocs topDocs = searcher.search(query, maxHits);
ScoreDoc[] hits = topDocs.scoreDocs;
for (int i = 0; i < hits.length; i++) {
int docId = hits[i].doc;
Document d = searcher.doc(docId);
System.out.println(d.get("filename"));
}
System.out.println("Found " + hits.length);
}