What is Kafka?
Kafka is a distributed streaming platform with three key capabilities:
- Publish & Subscribe: Read and write streams of data like a messaging system.
- Process: Write scalable stream processing application that react to events in real-time.
- Store: Store streams of data safely in a distributed, replicated, fault-tolerant cluster.
Kafka gets used for two broad classes of application:
- Building real-time streaming data pipelines that reliably get data between systems or applications.
- Building real-time streaming applications that transform or react to the streams of data.
Kafka gets used most often for streaming data into other systems: Feeds fast lane systems (real-time and operational data systems) like Storm, Flink, Spark Streaming and applications; Feeds data lake like Hadoop, RDBMS, Cassandra, Spark for some future data analysis, such as analytics, reporting, data science, backup and auditing.
Kafka’s Advantages:
- Kafka avoids copying buffers in-memory (Zero Copy), streams data to immutable logs sequentially instead of using random access which is fast!
- Kafka scales writes and reads by sharding topic logs into partitions which can be stored on multiple servers, and multiple consumers from multiple groups can read from different partitions efficiently.
- The consumer group concept generalizes messaging system: queuing and publish-subscribe. As with a queue the consumer group allows you to divide up the partitions over instances; As with publish-subscribe, Kafka allows you to broadcast messages to multiple consumer groups.
- By combining storage and low-latency subscriptions, streaming applications can treat both past and future data the same way.
- Kafka Stream facility helps solve the hard problems: handling out-of-order data, reprocessing input as code changes, performing stateful computations, etc.
Kafka Architecture
Kafka consists of Records, Topics, Consumers, Producers, Brokers, Logs, Partitions, and Clusters.
Topics and Logs
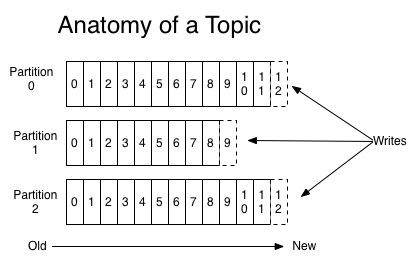
A topic is a feed name to which records are published and always multi-subscriber. For each topic, the cluster maintains a partitioned log. Each partition is an ordered, immutable sequence of records that is continually appended to. The records are each assigned a sequential id called the offset. The cluster retains all published records based on the retention policy.
Each partition has one server which acts as the “leader” and zero or more servers as “followers”. The leader handles all read and write requests for the partition while the followers passively replicate the leader. Each server acts as a leader for some of its partitions and a follower for others so load is well balanced within the cluster.
The Producer
The important concept here is that producer picks partition.
Load Balancing
The producer can sends data directly to the broker that is the leader for the partition without any intervening routing tier. To help the producer do this, all Kafka nodes can answer a request for metadata about which servers are alive and where the leaders for the partitions of a topic.
The producer/client controls which partition it publishes messages to. This can be done at a random or a round-robin strategy, or it can be done by some semantic partitioning function. The default partitioner for Java uses a hash of the record’s key.
For example if the key chosen was a user id then all data for a given user would be sent to the same partition. This in turn will allow consumers to make locality assumptions about their consumption.
Asynchronous Send
To enable batching the Kafka producer will attempt to accumulate data in memory and to send out larger batches in a single request. e.g. configured to accumulate no more than 64k messages and to wait no longer than 10ms. This buffering is configurable and used to trade off a small amount of additional latency for better throughput.
The Consumer
Consumers label themselves with a consumer group name, and each record published to a topic is delivered to one consumer instance within each subscribing consumer groups. Mostly each group is composed of many consumer instances for scalability and fault tolerance.
The way consumption is implemented in Kafka is by dividing up the partitions in the log over the consumer instances so that each instance is the exclusive consumer of a “fair share” of partitions at any point in time. The process of maintaining membership in the group is handled by the Kafka protocol dynamically.
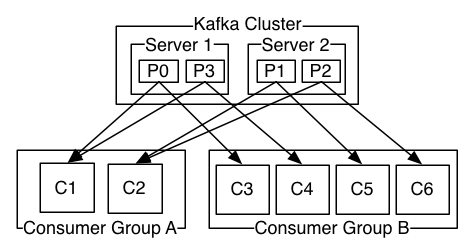
Kafka only provides a total order over records within a partition, not between different partitions in a topic. Per-partition ordering combined with the ability to partition data by key is sufficient for most applications. However, a total order over records can be achieved with a topic that has only one partition.
A consumer can see a record after the record gets fully replicated to all followers. If there are more consumers than partitions, the extra consumers remain idle until another consumer dies.
Use thread per consumer: Run multiple consumers in their own thread in the same JVM, each thread manages a share of partitions for that consumer group. The consumer groups have their own offset for every partition in the topic. A thread per consumer makes it easier to manage offsets. It is also simpler to manage failover.
If there’re more partitions than consumers in a group, some consumers will consume data from more than one partition. If there’re more consumers in a group than partitions, some consumers will get no data. If you add new consumer instances to the group, they will take over some partitions from old members. If you remove a consumer from the group (or the consumer dies), its partition will be reassigned to other member.
Pull-based
In a push system, the consumer tends to be overwhelmed when its rate of consumption falls below the rate of production (say a denial of service attack). A pull-based design fixes this as the consumer always pulls all available messages (with optimal batching) after its current position in the log.
With a pull-based system, if the broker has no data yet the consumer may end up polling in a tight loop. To avoid this we can tell pull request that allow the consumer request to block in a “long poll” waiting until a given number of bytes data arrives.
Consumer Position
Kafka handles this differently. Our topic is divided into a set of totally ordered partitions, each of which is consumed by exactly one consumer within each subscribing consumer group at any given time. This means that the position of a consumer in each partition is just a single integer, the offset of the next message to consume.This state can be periodically check-pointed. This makes the equivalent of message acknowledgements very cheap. Also a side benefit is a consumer can deliberately rewind back to an old offset and re-consume data.
Offline Data Load
Scalable persistence allows for the possibility of consumers that only periodically consume such as batch data loads that periodically bulk-load data into an offline system such as Hadoop or a relational data warehouse.
In the case of Hadoop we parallelize the data load by splitting the load over individual map tasks, one for each node/topic/partition combination, allowing full parallelism in the loading. Hadoop provides the task management, and tasks which fail can restart without danger of duplicate data - they simply restart from their original position.
Filesystem Persistence
- The modern OS provides read-ahead and write-behind techniques that prefetch data in a large block multiples and group smaller logical writes into large physical writes. Sequential disk access can in same cases be faster than random memory access!
- A modern OS becomes increasingly aggressive in their use of main memory for disk caching. All disk reads and writes will go through this unified cache. So even if a process maintains an in-process cache of data, this data will likely be duplicated in OS pagecache too.
- JVM has two disadvantages: The memory overhead of objects is very high, often doubling the size of the data stored; Java garbage collection becomes increasingly fiddly and slow as the in-heap data increases.
- As a result of these factors using the filesystem and relying on pagecache is superior to maintaining an in-memory cache or other structure. Even if the service is restarted, there is no need to rebuilt in-process cache in memory. So all data is immediately written to a persistent log on the filesystem without necessarily flushing to disk. In effect this just means that it is transferred into the kernel’s pagecache.
Complexity and Efficiency
- A persistent queue could be built on simple reads and appends to files, this structure has the advantage that all operations are O(1) and reads do not block writes or each other, the performance is completely decoupled from the data size.
- To prevent too many small I/O operations, Kafka is built around a “message set” abstraction that naturally groups messages together to reduce the overhead of the network roundtrip. The server in turn appends chunks of messages to its in one go. and the consumer fetches large linear chunks at a time.
- To avoid the inefficiency in byte copying, Kafka employs a standardized binary message format that is shared by the producer, broker and consumer. Which allows zero-copy optimization of the most important operation: network transfer of persistent log chunks. Using sendfile, the re-copying is avoided by allowing OS to send the data from pagecache to the network (NIC buffer) directly.
- Kafka supports end-to-end batch compression. A batch of messages can be clumped together compressed and sent between servers, then be written in compressed format in the log, and will only be decompressed by the consumer. Of course, the user can always compress its messages one at a time without any support need from Kafka, but this can lead to very poor compression ratios as much of the redundancy is due to repetition between messages of the same type (e.g. field names in JSON or user agents in web logs or common string values).
Message Delivery Semantics
How to guarantee each message is delivered (produced & consumed) once and only once?
Kafka’s producer supports an idempotent delivery option which guarantees that resending will not result in duplicate entries in the log. To achieve this, the broker assigns each producer an ID and deduplicates messages using a sequence number that is sent by the producer along with every message. Also supports the ability to send messages to multiple topic partitions using transaction-like semantics.
When consuming from a Kafka topic and producing to another topic (as a Kafka Streams application), we can leverage the new transactional producer capabilities. The consumer’s position is stored as a message in a topic, so we can write the offset to Kafka in the same transaction as the output topics receiving the processed data. If the transaction is aborted, the consumer’s position will revert to its old value and the produced data on the output topics will not be visible to other consumers.
When writing to an external system, the classic way of achieving this would be to introduce a two-phase commit between the storage of the consumer position and the storage of the consumers output. But this can be handled more simply and generally by letting the consumer store its offset in the same place as its output, consider Kafka Connect.
Replication
The unit of replication is the topic partition. Under non-failure conditions, each partition in Kafka has a single leader and zero or more followers. All reads and writes go to the leader of the partition. Typically there are many more partitions than brokers and the leaders are evenly distributed among brokers.
Followers consume messages from the leader just as a normal consumer would and apply them to their own log. Having the followers pull from the leader has the nice property of allowing the follower to naturally batch together log entries they are applying to their log.
The leader keeps track of the set of “in sync” nodes. If a follower dies, gets stuck, or falls behind, the leader will remove it from the list of in sync replicas, which is controlled by the replica.lag.time.max.ms configuration.
A message is considered committed when all in sync replicas for that partition have applied it to their log. Only committed messages are ever given out to the consumer. Producers, on the other hand, have the option (acks setting) of either waiting for the messages to be committed or not, depending on their preference for tradeoff between latency and durability.
Replicated Logs: ISRs
Kafka takes a slightly different approach to choose its quorum set. Instead of majority vote, Kafka dynamically maintains a set of in-sync replicas (ISR) that are caught-up to the leader. Only members of this set are eligible for election as leader. A write to a Kafka partition is not consider committed until all in-sync replicas have received the write. This ISR set is persisted to ZooKeeper whenever it changes. Because of this, any replica in the ISR is eligible to be elected leader. This is an important factor for Kafka’s usage model where there are many partitions and ensuring leadership balance is important. With this ISR model and f+1 replicas, a Kafka topic can tolerate f failures without losing committed messages.
Another important design distinction is that Kafka does not require that crashed nodes recover with all their data intact. The protocol for allowing a replica to rejoin the ISR ensures that before rejoining, it must fully re-sync again even if it lost unflushed data in its crash.
Unclean Leader Election
If all the nodes replicating a partition die, a practical system has two behaviors that could be implemented:
- Wait for a replica in the ISR to come back to life and choose this replica as the leader (hopefully it still has all its data).
- Choose the first replica (not necessarily in the ISR) that comes back to life as the leader.
This is simple tradeoff between availability and consistency. If we wait for replicas in the ISR, then we will remaining unavailable as long as those replicas are down; If, on the other handle, a non-in-sync replica comes back to life and we allow it to become leader, then its log becomes the source of truth even though it is not guaranteed to have every committed message.
When writing to Kafka, producers can choose whether they wait for the message to be acknowledged by 0, 1 or all (-1) replicas. Note that all does not guarantee that the full set of assigned replicas have received the message, but all the current in-sync replicas have received the message. You can specify a minimum ISR size: the partition will only accept writes if the size of the ISR is above a certain minimum.
Replica Management
Kafka attempts to balance partitions within a cluster in a round-robin fashion to avoid clustering all partitions for high-volume topics on a small number of nodes. It’s also important to optimize the leadership election process as that is the critical window of unavailability. Kafka will elect one of the brokers as the “controller”. This controller detects failures at the broker level and is responsible for changing the leader of all affected partitions in a failed broker. The result is that we are able to batch together many of the required leadership change notifications which makes the election process far cheaper and faster for a large number of partitions.
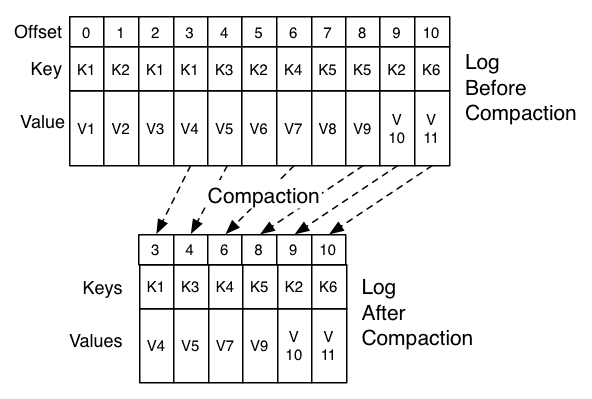
Log Compaction
Here log compaction is NOT log compression! Log compaction ensures that Kafka will always retain at least the last known value for each message key within the log of data for a single topic partition. The downstream consumers can restore their own state off this topic without having to retain a complete log of all changes.
For example, we have a topic containing user email addresses; every time a user updates their email address we send a message to this topic using their user id as the primary key. Now say we send the following messages over some time period for a user with id 123, each message corresponding to a change in email address:
1 123 => bill@microsoft.com
2 .
3 .
4 .
5 123 => bill@gatesfoundation.org
6 .
7 .
8 .
9 123 => bill@gmail.com
Log compaction is a mechanism to give finer-grained per-record retention, rather than the coarser-grained time-based retention. The idea is to selectively remove records where we have a more recent update with the same primary key. this way the log is guaranteed to have at least the last state for each key.
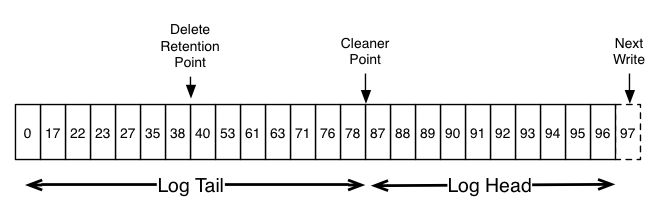
The head of the log is identical to a traditional Kafka log. It has dense, sequential offsets and retains all messages. The compacted tail retain the original offset assigned, and remain valid positions in the log, even if the message with that offset has been compacted away. In the picture the offsets 36, 37 and 38 are all equivalent positions.
Compaction also allows for deletes. A message with a key and a null payload will be treated as a delete from the log. This delete marker will cause any prior message with the key to be removed, but even delete markers themselves will be cleaned out of the log after a period of time (marked as “delete retention point”) to free up space.
The compaction is handled by the log cleaner, a pool of background threads that recopy log segment files, removing records whose key appears in the head of the log. Each compactor thread work as follows:
- It choose the log that has the highest ratio of log head to log tail.
- It creates a succinct summary of the last offset for each key in the head of the log.
- It recopies the log from beginning to end removing keys which have a later occurrence in the log. New, clean segments are swapped into the log immediately so the additional disk space required is just one additional log segment.
- The summary of the log head is essentially just a space-compact hash table.
The log.cleaner.min.compaction.lag.ms can be configured to retain a minimum amount of the uncompacted “head” of the log.
Quotas
Kafka cluster has the ability to enforce quotas on requests to control the broker resources used by clients (user, client-id).
-
Network Bandwidth Quota is defined on a per-broker basis. Each group of clients can publish/fetch a maximum of X bytes/sec per broker before clients are throttled.
-
Request Rate Quota is defined as the percentage of time a client can utilized on request handler I/O threads and network threads of each broker within a quota window, which represent the total percentage of CPU.
Defining these quotas per broker is much better than having a fixed cluster wide bandwidth per client because that would require a mechanism to share client quota usage among all the brokers.
When detects a quota validation. The broker does not return an error rather it attempts to slow down a client exceeding its quota. This keeps the quota violation transparent to client and keeps them from having to implement any special backoff and retry behavior which can get tricky.
Byte-rate and thread utilization are measured over multiple small windows (e.g. 30 windows of 1 second each) in order to detect and correct quota violations quickly.
Kafka Needs ZooKeeper
- To do leadership election of Broker and Topic Partition pairs.
- To manage service discovery for Kafka Brokers that form the cluster.
- ZooKeeper sends changes of the topology to Kafka, like a broker joined/died, a topic removed/added.
- ZooKeeper provides an in-sync view of Kafka cluster configuration.
- A typical ZooKeeper’s quorum set, ensemble with 5 or 7 servers, which tolerates 2 and 3 servers down.
- It’s java, make sure you give it ‘enough’ heap space (usually with 3-5G).
Kafka Core APIs
Producer API
The producer is thread safe and sharing a single producer instance across threads will generally be faster than having multiple instances. Because the producer consists of a pool of buffer space that holds records that haven’t yet been transmitted to the servers as well as a background I/O thread that is responsible for turning these records into requests and transmitting them to the cluster. Failure to close the producer after use will leak these resources.
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all"); // 0, 1, all (ISRs)
props.put("retries", 0); // enable retries could open up the duplicates.
props.put("batch.size", 16384);
props.put("linger.ms", 1); // delay sending so more records might arrive into the same batch.
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++)
// The send() method is asynchronous, allows to batch together individual records for efficiency.
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));
producer.close();
- The transactional producer allows an application to send messages to multiple partitions (and topics!) atomically. To use the transactional producer and the attendant APIs:
- You must set the transactional.id configuration property.
- Enable idempotence, the enable.idempotence configuration must be set to true.
- Topics which are included in transactions should be configured for durability. In particular, the replication.factor should be at lease 3, and the min.insync.replicas for these topics should be set to 2.
- Finally, the consumers must be configured to read only committed messages as well.
-
The purpose of the transactional.id is to enable transaction recovery across multiple sessions of a single producer instance. It would typically be derived from the shard identifier in a partitioned, stateful, application. As such it should be unique to each producer instance running within a partitioned application.
- There can be only one open transaction per producer. All messages sent between the beginTransaction() and commitTransaction() calls will be part of a single transaction. The transactional producer uses exceptions to communicate error states. In particular, it’s not required to specify callbacks for producer.send() or to call .get() on the returned Future.
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("transactional.id", "my-transactional-id");
Producer<String, String> producer = new KafkaProducer<>(props, new StringSerializer(), new StringSerializer());
producer.initTransactions();
try {
producer.beginTransaction();
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<>("my-topic", Integer.toString(i), Integer.toString(i)));
producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
// We can't recover from these exceptions, so our only option is to close the producer and exit.
producer.close();
} catch (KafkaException e) {
// For all other exceptions, just abort the transaction and try again.
producer.abortTransaction();
}
producer.close();
Consumer API
The consumer is not thread safe. It transparently handles the failure of Kafka brokers, and transparently adapts as topic partitions it fetches migrate within the cluster. Also interacts with the broker to allow groups of consumers to load balance consumption using consumer groups.
-
The consumer maintains TCP connections to the necessary brokers to fetch data. Failure to close the consumer after use will leak these connections.
-
The position of the consumer gives the offset of the next record that will be given out; The committed position is the last offset that has been processed securely. Should the process fail and restart, this is the offset that the consumer will recover to.
Consumer Groups and Topic Subscriptions
-
Kafka uses the concept of consumer groups to allow a pool of processes (consumers) to divide the work of consuming and processing records. All consumer instances sharing the same group.id will be part of the same consumer group.
-
Each consumer in a group can dynamically set the list of topics it wants to subscribe to through one of the subscribe APIs. Kafka will balance the partitions between all members in the consumer group so that each partition is assigned to exactly one consumer in the group.
-
Membership in a consumer group is maintained dynamically: if a process fails, the partitions assigned to it will be reassigned to other consumers in the same group. Similarly, if a new consumer joins the group, partitions will be moved from existing consumers to the new one. This is known as rebalancing the group and is discussed in more detail below. Group rebalancing is also used when new partitions are added to one of the subscribed topics or when a new topic matching a subscribed regex is created. The group will automatically detect the new partitions through periodic metadata refreshes and assign them to members of the group.
-
When group reassignment happens automatically, consumers can be notified through a ConsumerRebalanceListener, which allows them to finish necessary application-level logic such as state cleanup, manual offset commits, etc. It is also possible for the consumer to manually assign specific partitions using assign(Collection).
Detecting Consumer Failures
After subscribing to a set of topics, the consumer will automatically join the group when poll(long) is invoked. The poll API is designed to ensure consumer liveness. As long as you continue to call poll, the consumer will stay in the group and continue to receive messages from the partitions it was assigned. Underneath the covers, the consumer sends periodic heartbeats to the server. If the consumer crashes or is unable to send heartbeats for a duration of session.timeout.ms, then the consumer will be considered dead and its partition will be reassigned.
The consumer provide two configuration settings to control the behavior of the poll loop:
- max.poll.interval.ms: By increasing the interval between expected polls, you can give the consumer more time to handle a batch of records returned from poll(long).
- max.poll.records: Use this setting to limit the total records returned from a single call to poll.
The recommended way to handle the use cases, where message processing time varies unpredictably, is to move message processing to another thread, which allows the consumer to continue calling poll while the processor is still working. To ensure the committed offsets do not get ahead of the actual position. you must disable automatic commits and manually commit processed offsets for records only after the thread has finished handling them.
Automatic Offset Committing
Properties props = new Properties();
// This list is just used to discover the rest of the brokers in the cluster
// and need not be an exhaustive list of servers in the cluster.
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
// Offsets are committed automatically with a frequency
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
Manual Offset Control
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "false");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
final int minBatchSize = 200;
List<ConsumerRecord<String, String>> buffer = new ArrayList<>();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
buffer.add(record);
}
if (buffer.size() >= minBatchSize) {
insertIntoDb(buffer);
consumer.commitSync();
buffer.clear();
}
}
The above example uses commitSync to mark all received records as committed. You can even commit offset after we finish handling the records in each partition.
try {
while(running) {
ConsumerRecords<String, String> records = consumer.poll(Long.MAX_VALUE);
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) {
System.out.println(record.offset() + ": " + record.value());
}
long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)));
}
}
} finally {
consumer.close();
}
Manual Partition Assignment
String topic = "foo";
TopicPartition partition0 = new TopicPartition(topic, 0);
TopicPartition partition1 = new TopicPartition(topic, 1);
consumer.assign(Arrays.asList(partition0, partition1));
Storing Offsets Outside Kafka
Each record comes with its own offset, so to manage your own offset you just need to do the following:
- Configure enable.auto.commit=false
- Use the offset provided with each ConsumerRecord to save your position.
- On restart restore the position of the consumer using seek(TopicPartition, long).
If the partition assignment is done automatically special care is needed to handle the case where partition assignments change. This can be done by providing a ConsumerRebalanceListener instance in the call to subscribe(Collection, ConsumerRebalanceListener) and subscribe(Pattern, ConsumerRebalanceListener).
For example, when partitions are taken from a consumer the consumer will want to commit its offset for those partitions by implementing ConsumerRebalanceListener.onPartitionsRevoked(Collection). When partitions are assigned to a consumer, the consumer will want to look up the offset for those new partitions and correctly initialize the consumer to that position by implementing ConsumerRebalanceListener.onPartitionsAssigned(Collection).
Kafka allows specifying the position using seek(TopicPartition, long) to specify the new position. Special methods for seeking to the earliest and latest offset the server maintains are also available ( seekToBeginning(Collection) and seekToEnd(Collection) respectively).
If consumers want to first focus on fetching from some subset of the assigned partitions at full speed, and only start fetching other partitions later. Kafka supports dynamic controlling of consumption flows by using pause(Collection) and resume(Collection) to control consumption flow in the poll loop calls.
Reading Transactional Messages
Transactions were introduced in Kafka 0.11.0 wherein applications/producers can write to multiple topics and partitions atomically. In order for this to work, consumers reading from these partitions should be configured to only read committed data. Set the isolation.level=read_committed in the consumer’s configuration.
Partitions with transactional messages will include commit or abort markers which indicate the result of a transaction. As a result, the consumer side will see gaps in the consumed offsets.
Multi-threaded Processing
It’s the responsibility of the user to ensure that multi-threaded access is properly synchronized. The wakeup() can safely be used from an external thread to interrupt an active operation (shutdown).
public class KafkaConsumerRunner implements Runnable {
private final AtomicBoolean closed = new AtomicBoolean(false);
private final KafkaConsumer consumer;
public void run() {
try {
consumer.subscribe(Arrays.asList("topic"));
while (!closed.get()) {
ConsumerRecords records = consumer.poll(10000);
// Handle new records
// NOTE: We can use 2nd layer of multi-threaded processors here!
}
} catch (WakeupException e) {
// Ignore exception if closing
if (!closed.get()) throw e;
} finally {
consumer.close();
}
}
// Shutdown hook which can be called from a separate thread
public void shutdown() {
closed.set(true);
consumer.wakeup();
}
}
Here we can discuss two options for implementing multi-threaded processing of records:
- One Consumer Per Thread
A simple option is to give each tread its own consumer instance. Here are the pros and cons of this approach:
- PRO: It is the easiest to implement
- PRO: It is often the fastest as no inter-thread co-ordination is needed
- PRO: It makes in-order processing on a per-partition basis very easy to implement
- CON: More consumers means more TCP connections to the cluster (one per thread). In general Kafka handles connections very efficiently so this is generally a small cost.
- CON: Multiple consumers means more requests being sent to the server and slightly less batching of data which can cause some drop in I/O throughput.
- CON: The number of total threads across all processes will be limited by the total number of partitions.
- Decouple Consumption and Processing
Another alternative is to have one or more consumer threads that do all data consumption and hands off ConsumerRecords instances to a blocking queue consumed by a pool of processor threads that actually handle the record processing.
- PRO: This option allows independently scaling the number of consumers and processors.
- CON: Guaranteeing order across the processors requires particular care.
- CON: Manually committing the position becomes harder.
- One Consumer Per Thread + Multi Processors in Thread
- Initialize a small list of threads which will have their own consumer.
- Within each thread, we use a pool of processor threads that handle the records.
Stream API
Without Kafka Stream, to do real-time processing, our options are:
- Write you own custom code with a KafkaConsumer to read the data and write that data via a KafkaProducer.
- Use a full-fledged stream processing framework like Spark Streaming, Flink, Storm, etc.
Kafka Stream is a client library for building mission-critical real-time applications and microservices, where the input and output data are stored in Kafka clusters.
The code example below implements a WordCount application:
public class WordCountApplication {
public static void main(final String[] args) throws Exception {
Properties config = new Properties();
config.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application");
config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-broker1:9092");
config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> textLines = builder.stream("TextLinesTopic");
KTable<String, Long> wordCounts = textLines
// Split each text line into words
.flatMapValues(textLine -> Arrays.asList(textLine.toLowerCase().split("\\W+")))
// Group the text words as message keys
.groupBy((key, word) -> word)
// Count the occurrences of each word
.count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as("counts-store"));
// Store the running counts as a changelog stream to the output topic
wordCounts.toStream().to("WordsWithCountsTopic", Produced.with(Serdes.String(), Serdes.Long()));
KafkaStreams streams = new KafkaStreams(builder.build(), config);
streams.start();
}
}
Prepare input topic and start Kafka producer
Next, we create the input topic named streams-plaintext-input and the output topic named streams-wordcount-output:
bin/kafka-topics.sh –create
–zookeeper localhost:2181
–replication-factor 1
–partitions 1
–topic streams-plaintext-input
We create the output topic with compaction enabled because the output stream is a changelog stream:
bin/kafka-topics.sh –create
–zookeeper localhost:2181
–replication-factor 1
–partitions 1
–topic streams-wordcount-output
–config cleanup.policy=compact
Process some data
bin/kafka-console-producer.sh –broker-list localhost:9092 –topic streams-wordcount-input all streams lead to kafka hello kafka streams join kafka summit
bin/kafka-console-consumer.sh –bootstrap-server localhost:9092 –topic streams-wordcount-output
–from-beginning
–formatter kafka.tools.DefaultMessageFormatter
–property print.key=true
–property print.value=true
–property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer
–property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
| Processed First Text Line | Processed Second Text Line |
|---|---|
| “all streams lead to kafka” | “hello kafka streams” |
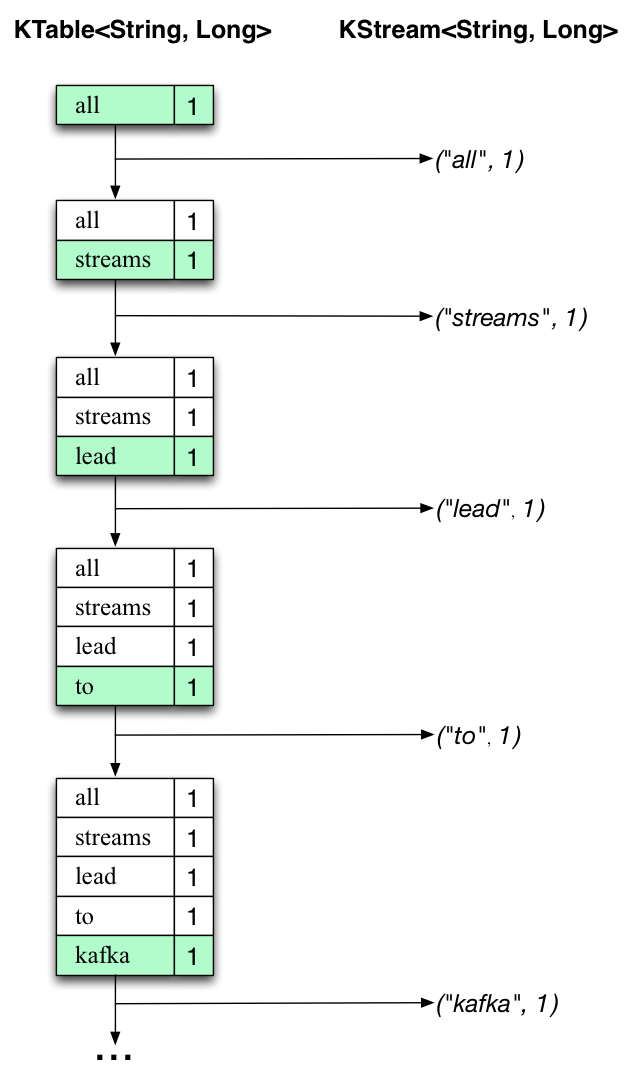 |
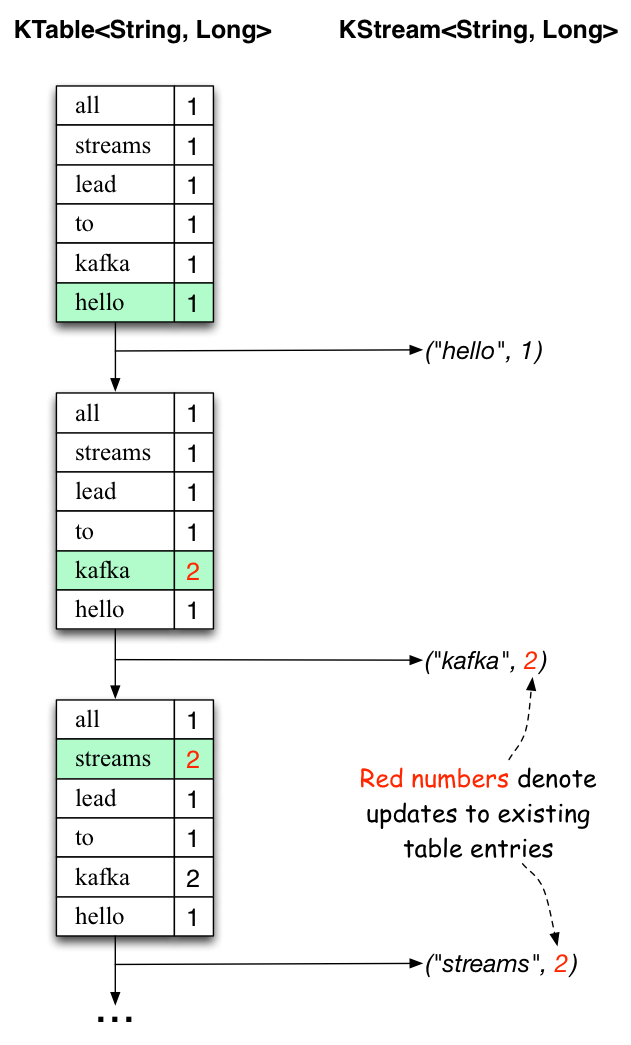 |
Stream Processing Topology
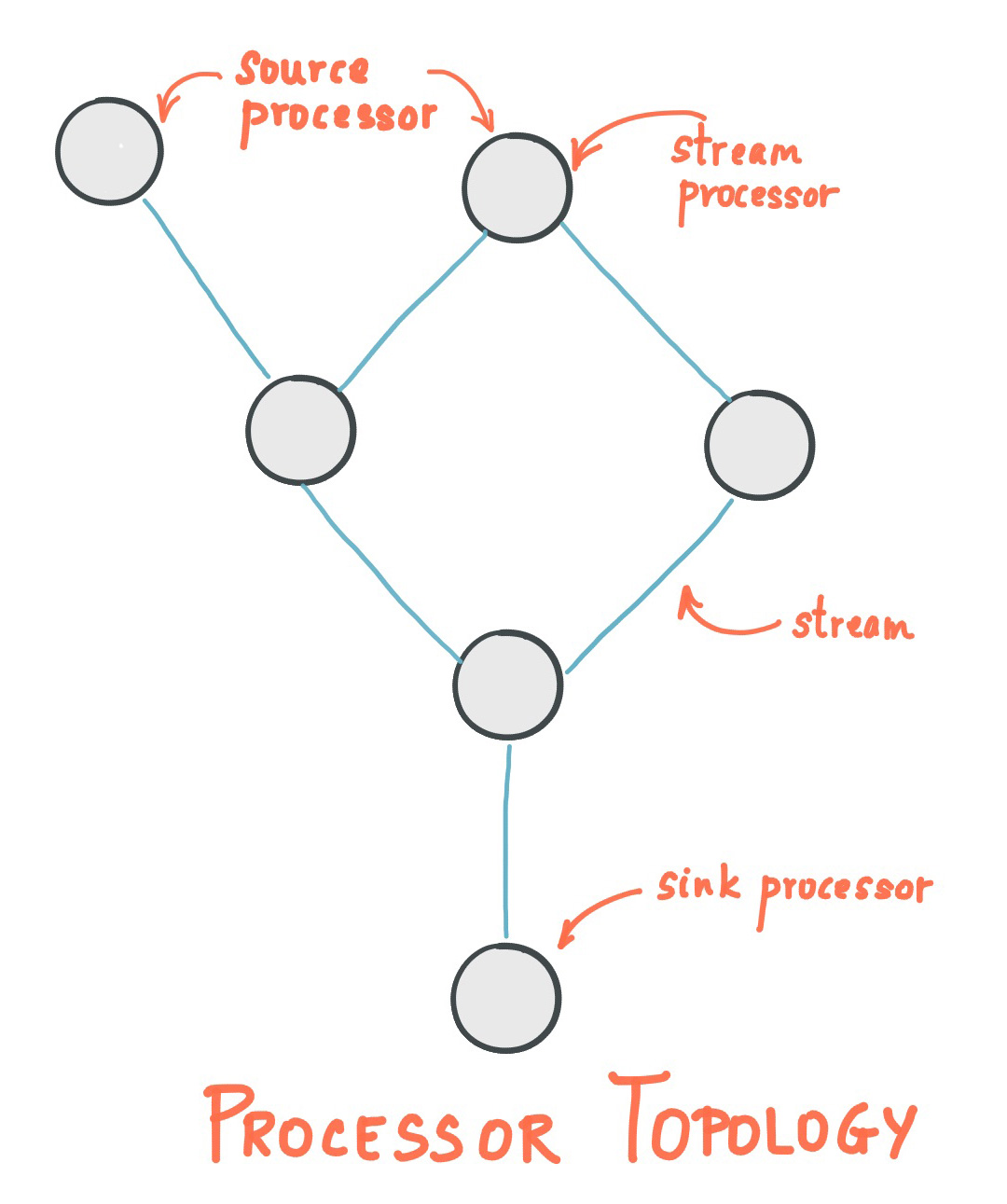
A critical aspect in stream processing is the notion of time, and how it is modeled and integrated. Common notions of time in streams are: Event time; Processing time; Ingestion time.
Kafka Streams provides so-called state stores, which can be used by to store and query data. These state stores can either be a persistent key-value store, an in-memory hashmap, or another convenient data structure.
High-Level DSL
High-Level DSL contains already implemented methods ready to use. It is composed of two main abstractions: KStream and KTable or GlobalKTable.
Available stateful transformations in the DSL include:
- Aggregating
- Joining
- Windowing
- Applying custom processors and transformers
Processor API
Low-Level Processor API provides you the flexibility to implement processing logic to your need. The trade-off is just the lines of code you need to write for specific scenarios.
Processor API
The Processor API allows developers to define and connect custom processors and to interact with state stores. A stream processor is a node in the processor topology that represents a single processing step.
public class WordCountProcessor implements Processor<String, String> {
private ProcessorContext context;
private KeyValueStore<String, Long> kvStore;
@Override
@SuppressWarnings("unchecked")
public void init(ProcessorContext context) {
// keep the processor context locally because we need it in punctuate() and commit()
this.context = context;
// retrieve the key-value store named "Counts"
kvStore = (KeyValueStore) context.getStateStore("Counts");
// schedule a punctuate() method every 1000 milliseconds based on stream-time
this.context.schedule(1000, PunctuationType.STREAM_TIME, (timestamp) -> {
KeyValueIterator<String, Long> iter = this.kvStore.all();
while (iter.hasNext()) {
KeyValue<String, Long> entry = iter.next();
context.forward(entry.key, entry.value.toString());
}
iter.close();
// commit the current processing progress
context.commit();
});
}
@Override
public void punctuate(long timestamp) {
// this method is deprecated and should not be used anymore
}
@Override
public void close() {
// close the key-value store
kvStore.close();
}
}
You can create two store types out of the box now: Persistent (RocksDB) and In-memory.
import org.apache.kafka.streams.state.StoreBuilder;
import org.apache.kafka.streams.state.Stores;
StoreBuilder<KeyValueStore<String, Long>> countStoreSupplier = Stores.keyValueStoreBuilder(
Stores.persistentKeyValueStore("Counts"),
Serdes.String(),
Serdes.Long())
.withLoggingDisabled(); // disable backing up the store to a changelog topic
Streams DSL
The Kafka Streams DSL (Domain Specific Language) is built on top of the Streams Processor API.
Aggregate (windowed)
import java.util.concurrent.TimeUnit;
KGroupedStream<String, Long> groupedStream = ...;
// Java 8+ examples, using lambda expressions
// Aggregating with time-based windowing (here: with 5-minute tumbling windows)
KTable<Windowed<String>, Long> timeWindowedAggregatedStream = groupedStream.windowedBy(TimeUnit.MINUTES.toMillis(5))
.aggregate(
() -> 0L, /* initializer */
(aggKey, newValue, aggValue) -> aggValue + newValue, /* adder */
Materialized.<String, Long, WindowStore<Bytes, byte[]>>as("time-windowed-aggregated-stream-store") /* state store name */
.withValueSerde(Serdes.Long())); /* serde for aggregate value */
// Aggregating with session-based windowing (here: with an inactivity gap of 5 minutes)
KTable<Windowed<String>, Long> sessionizedAggregatedStream = groupedStream.windowedBy(SessionWindows.with(TimeUnit.MINUTES.toMillis(5)).
aggregate(
() -> 0L, /* initializer */
(aggKey, newValue, aggValue) -> aggValue + newValue, /* adder */
(aggKey, leftAggValue, rightAggValue) -> leftAggValue + rightAggValue, /* session merger */
Materialized.<String, Long, SessionStore<Bytes, byte[]>>as("sessionized-aggregated-stream-store") /* state store name */
.withValueSerde(Serdes.Long())); /* serde for aggregate value */
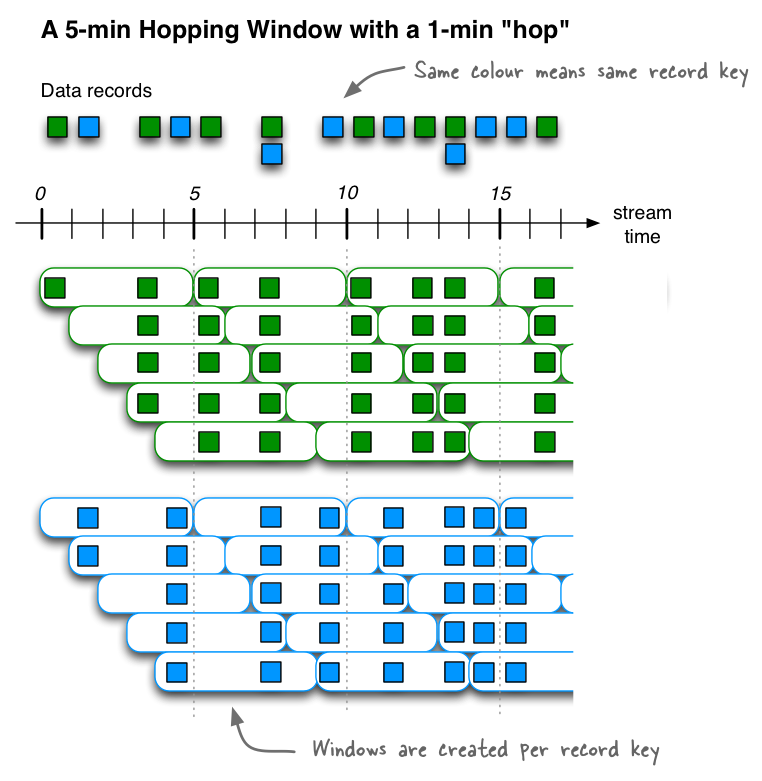
Hopping time windows
Windowing lets you control how to group records that have the same key for stateful operations such as aggregations or joins into so-called windows. Windows are tracked per record key.
For example, in join operations, a windowing state store is used to store all the records received so far within the defined window boundary. In aggregating operations, a windowing state store is used to store the latest aggregation results per window. Old records in the state store are purged after the specified window retention period. Kafka Streams guarantees to keep a window for at least this specified time; the default value is one day and can be changed via Windows#until() and SessionWindows#until().
import java.util.concurrent.TimeUnit;
import org.apache.kafka.streams.kstream.TimeWindows;
// A hopping time window with a size of 5 minutes and an advance interval of 1 minute.
// The window's name -- the string parameter -- is used to e.g. name the backing state store.
long windowSizeMs = TimeUnit.MINUTES.toMillis(5); // 5 * 60 * 1000L
long advanceMs = TimeUnit.MINUTES.toMillis(1); // 1 * 60 * 1000L
TimeWindows.of(windowSizeMs).advanceBy(advanceMs);
Memory Management
You can specify the total memory (RAM) size used for internal caching and compacting of records. This caching happens before the records are written to state stores or forwarded downstream to other nodes.
The record caches are implemented slightly different in the DSL and Processor API.
-
An aggregation computes the sum of record values, grouped by key, for the input and returns a KTable<String, Integer>.
- Without caching: a sequence of output records is emitted for key A that represent changes in the resulting aggregation table. The parentheses (()) denote changes, the left number is the new aggregate value and the right number is the old aggregate value: <A, (1, null)>, <A, (21, 1)>, <A, (321, 21)>.
- With caching: a single output record is emitted for key A that would likely be compacted in the cache, leading to a single output record of <A, (321, null)>. This record is written to the aggregation’s internal state store and forwarded to any downstream operations.
To avoid high write traffic it is recommended to enable RocksDB caching if Kafka Streams caching is turned off.
Kafka Implementation
Network Layer
The sendfile implementation is done by giving MessageSet interface a writeTo method. This allows the file-backed message set to use the more efficient transferTo implementation instead of an in-process buffered write.
Message Format
Record Batch
Messages are always written in batches. A batch of messages is a record batch. The following is the on-disk format of a RecordBatch:
baseOffset: int64
batchLength: int32
partitionLeaderEpoch: int32
magic: int8 (current magic value is 2)
crc: int32
attributes: int16
bit 0~2:
0: no compression
1: gzip
2: snappy
3: lz4
bit 3: timestampType
bit 4: isTransactional (0 means not transactional)
bit 5: isControlBatch (0 means not a control batch)
bit 6~15: unused
lastOffsetDelta: int32
firstTimestamp: int64
maxTimestamp: int64
producerId: int64
producerEpoch: int16
baseSequence: int32
records: [Record]
It’s possible to have empty batches in the log when all the records in the batch are cleaned but batch is still retained in order to preserve a producer’s last sequence number.
Record
length: varint
attributes: int8
bit 0~7: unused
timestampDelta: varint
offsetDelta: varint
keyLength: varint
key: byte[]
valueLen: varint
value: byte[]
Headers => [Header]
Record Header
headerKeyLength: varint
headerKey: String
headerValueLength: varint
Value: byte[]
Varints are a method of serializing integers using one or more bytes instead of fixed bytes. Smaller numbers take a smaller number of bytes.
Each byte in a varint, except the last byte, has the most significant bit (msb) set - this indicates that there are future bytes to come. The lower 7 bits of each byte are used to store the two’s complement representation of the number in groups of 7 bits, least significant group first.
96 01 = 1001 0110 0000 0001
→ 000 0001 ++ 001 0110 (drop the msb and reverse the groups of 7 bits)
→ 10010110
→ 128 + 16 + 4 + 2 = 150
Log
The use of the message offset as the message id is unusual. To simplify the lookup structure we use a simple per-partition atomic counter which could be coupled with the partition id and node id to uniquely identify a message; this makes the lookup structure simpler, though multiple seeks per consumer request are still likely.
Read
The actual process of reading from an offset requires first locating the log segment file in which the data is stored, calculating the file-specific offset from the global offset value, and then reading from that file offset. The search is done as a simple binary search variant against an in-memory range maintained for each file.
The following is the format of the results send to the consumer:
MessageSetSend (fetch result)
total length : 4 bytes
error code : 2 bytes
message 1 : x bytes
...
message n : x bytes
MultiMessageSetSend (multiFetch result)
total length : 4 bytes
error code : 2 bytes
messageSetSend 1
...
messageSetSend n
Delete
Data is deleted one log segment at a time. To avoid locking reads while still allowing deletes that modify the segment list we use a copy-on-write style segment list implementation that provides consistent views to allow a binary search to proceed on an immutable static snapshot view of the log segments while deletes are processing.
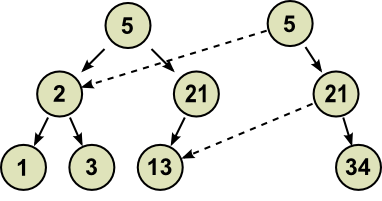
Copy-on-write is an optimization strategy used in computer programming. The fundamental idea is that if multiple callers ask for resources which are initially indistinguishable, you can given them pointers to the same resource. This function can be maintained until a caller tries to modify its “copy” of the resource, at which point a true private copy is created to prevent the changes becoming visible to everyone else. All of this happens transparently to the callers. The primary advantage is that if a caller never makes any modifications, no private copy need ever be created.
Using copy-on-write to modify a binary tree. Once you have done and created a binary tree, you can never ever change it, over here in the wacky world of copy-on-write you have to create a modified copy instead of actually modifying anything. But you don’t need to take a full copy, in general, if you’re updating one node, taking a modified copy of a tree will require copying only the path from the root node of the tree to the affected node. That’s how copy-on-write trees work: path copying.
Distribution
Consumer Offset Tracking
The high-level consumer tracks the maximum offset it has consumed in each partition and periodically commits its offset vector so that it can resume from those offsets in the event of a restart. Kafka provides the option to store all the offsets for a given consumer group in a designated broker (for that group) called the offset manager or use ZooKeeper. The offset manager also caches the offsets in an in-memory table in order to serve offset fetches quickly.
ZooKeeper Directories
Broker Node Registry
/brokers/ids/[0…N] –> {“jmx_port”:…,”timestamp”:…,”endpoints”:[…],”host”:…,”version”:…,”port”:…} (ephemeral node)
Broker Topic Registry
/brokers/topics/[topic]/partitions/[0…N]/state –> {“controller_epoch”:…,”leader”:…,”version”:…,”leader_epoch”:…,”isr”:[…]} (ephemeral node)
Each broker registers itself under the topics it maintains and stores the number of partitions for that topic.
Consumers and Consumer Groups
Consumers of topics also register themselves in ZooKeeper, in order to coordinate with each other and balance the consumption of data.
/consumers/[group_id]/ids/[consumer_id] –> {“version”:…,”subscription”:{…:…},”pattern”:…,”timestamp”:…} (ephemeral node)
Cluster Id
The cluster id is a unique and immutable identifier assigned to a Kafka cluster.
Operations
Adding and Removing Topics
Topics can be auto-created or added manually, For each partition must fit entirely on a single server.
bin/kafka-topics.sh –zookeeper zk_host:port/chroot –create –topic my_topic_name –partitions 20 –replication-factor 3 –config x=y
To add partitions:
bin/kafka-topics.sh –zookeeper zk_host:port/chroot –alter –topic my_topic_name –partitions 40
To add configs:
bin/kafka-configs.sh –zookeeper zk_host:port/chroot –entity-type topics –entity-name my_topic_name –alter –add-config x=y
Balacing Replicas Across Racks
You can specify that a broker belongs to a particular rack by adding a property to the broker config:
broker.rack=my-rack-id
Mirroring data between Clusters
Here is an example showing how to mirror a single topic (named my-topic) from an input cluster:
bin/kafka-mirror-maker.sh –consumer.config consumer.properties –producer.config producer.properties –whitelist my-topic
Stream Processing
Stream processing refers to the ongoing processing of one or more event streams. Stream processing is a continuous and nonblocking option. Filling the gap between the request-response world where we wait for events that take two milliseconds to process and the batch processing world where data processed once a day and take hours to complete.
There are a few attributes of event streams model: Unbounded dataset, Event streams are ordered, Immutable data records, Event streams are replayable.
For example, our stream application might calculate a moving five-minute average of stock prices. In that case, we need to know what to do when one of our producers goes offline for two hours due to network issues and returns with two hours worth of data—most of the data will be relevant for five-minute time windows that have long passed and for which the result was already calculated and stored.
In order to convert a stream to a table, we need to apply all the changes that the stream contains. This is also called materializing the stream. We create a table, either in memory, in an internal state store, or in an external database, and start going over all the events in the stream from beginning to end, changing the state as we go. When we finish, we have a table representing a state at a specific time that we can use.
How often the window moves (advance interval): five-minute averages can update every minute, second, or every time there is a new event. When the advance interval is equal to the window size, this is sometimes called a tumbling window. When the window moves on every minute, it’s called hopping window; When the window moves on every record, this is sometimes called a sliding window.
Persistence
We need to make sure the state is not lost when an application instance shuts down, and that the state can be recovered when the instance starts again or is replaced by a different instance. This is something that Kafka Streams handles very well—local state is stored in-memory using embedded RocksDB, which also persists the data to disk for quick recovery after restarts. But all the changes to the local state are also sent to a Kafka topic. If a stream’s node goes down, the local state is not lost—it can be easily recreated by rereading the events from the Kafka topic. For example, if the local state contains “current minimum for IBM=167.19,” we store this in Kafka, so that later we can repopulate the local cache from this data. Kafka uses log compaction for these topics to make sure they don’t grow endlessly and that recreating the state is always feasible.
Partitions sometimes are reassigned to a different consumer. When this happens, the instance that loses the partition must store the last good state, and the instance that receives the partition must know how to recover the correct state. Also, we can have State that is maintained in an external datastore, often a NoSQL system like Cassandra.
Multiphase Processing
This type of multiphase processing is very familiar to those who write map-reduce code, where you often have to resort to multiple reduce phases. Unlike MapReduce, most stream-processing frameworks allow including all steps in a single app, with the framework handling the details of which application instance (or worker) will run reach step.
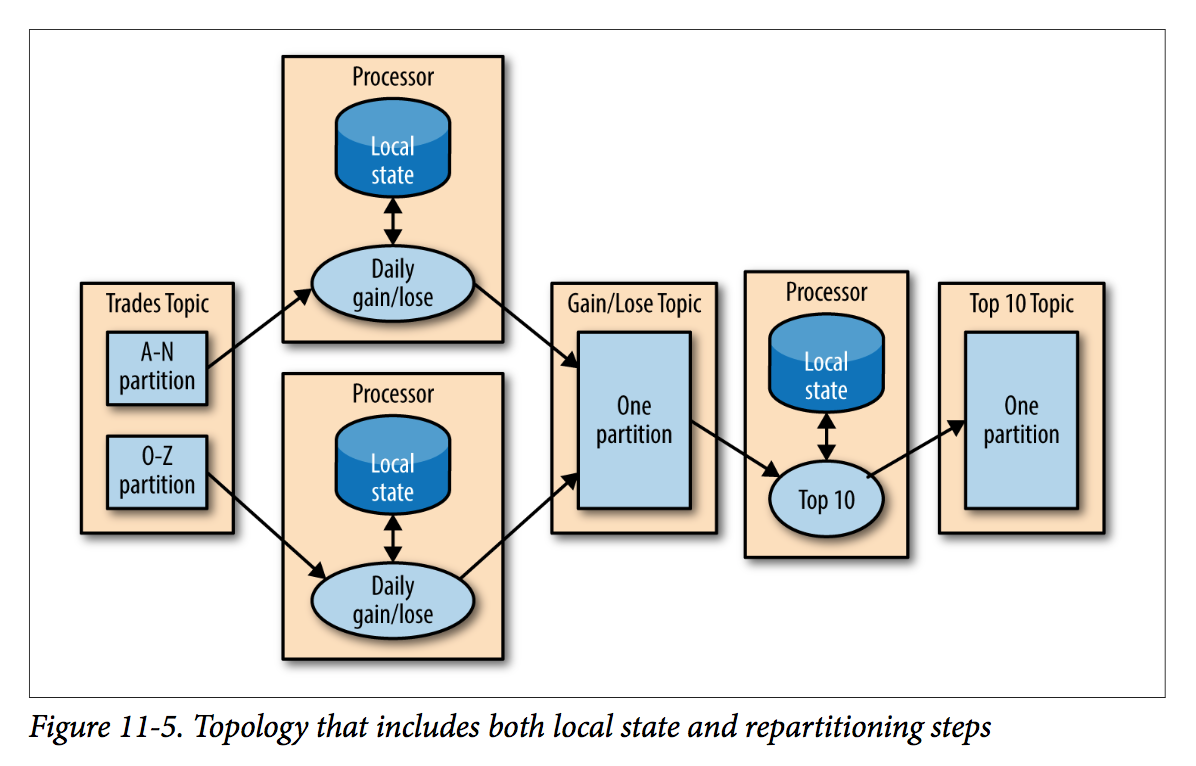
Processing with External Lookup: Stream-Table Join
The problem is an external lookup adds significant latency to the process of every record (100K-500K/sec vs 10K/sec). In order to get good performance and scale, we need to cache the information from the database in our stream-processing application.
So if we can capture all the changes that happen to the database table in a stream of events, we can have our stream-processing job listen to this stream and update the cache based on database change events.
Streaming Join
When you join two streams, you are joining the entire history, trying to match events in one stream with events in the other stream that have the same key and happened in the same time-windows. This is why a stream-join is also called a windowed-join.
For example, let’s say that we have one stream with search queries that people entered into our website and another stream with clicks, which include clicks on search results. We want to match search queries with the results they clicked on so that we will know which result is most popular for which query. Obviously we want to match results based on the search term but only match them within a certain time-window.
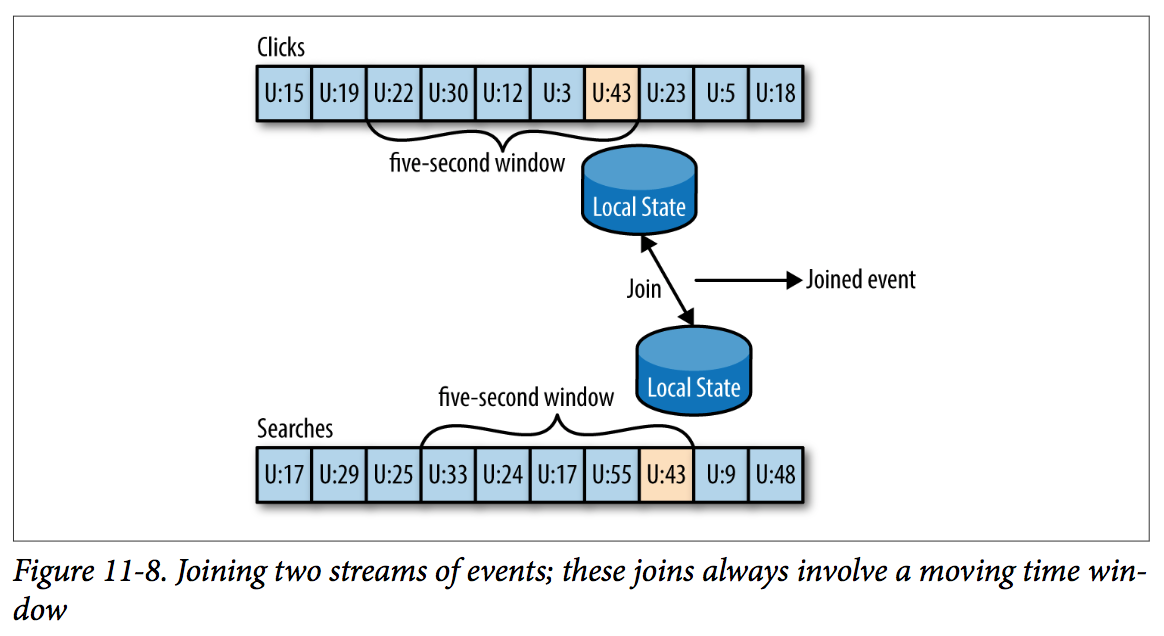
The way this works in Kafka Streams is that both streams, queries and clicks, are partitioned on the same keys, which are also the join keys. This way, all the click events from user_id:42 end up in partition 5 of the clicks topic, and all the search events for user_id:42 end up in partition 5 of the search topic. Kafka Streams then makes sure that partition 5 of both topics is assigned to the same task. So this task sees all the relevant events for user_id:42. It maintains the join-window for both topics in its embedded RocksDB cache, and this is how it can perform the join.
Out-of-Sequence Events
For example, a mobile device loses WiFi signal for a few hours and sends a few hours’s worth of events when it reconnects. Our stream applications need to recognize an event is out of sequence by checking the event time; define a time period during which it will attempt to reconcile (like within three-hour delay); have an in-band capability to reconcile this event; be able to update results.
Kafka Streams have built-in support for above case by maintaining multiple aggregation windows available for update in the local state and giving developers the ability to configure how long to keep those window aggregates available for updates. The aggregation results were written to compacted topics, which means that only the latest value for each key is preserved.
Reprocessing
The first case is we want to run the new version of the application on the same event stream as the old, compare the results between the two versions, and at some point move clients to use new results instead of the existing ones.
This means that having two versions of a stream processing-application writing two result streams only requires the following:
- Spinning up the new version of the application as a new consumer group
- Configuring the new version to start processing from the first offset of the input topics (so it will get its own copy of all events in the input streams)
- Letting the new application continue processing and switching the client applications to the new result stream when the new version of the processing job has caught up
The second case is the existing stream-processing app is buggy. We fix the bug and we want to reprocess the event stream and recalculate our results. It requires “resetting” an existing app to start processing back at the beginning of the input streams, resetting the local state, and possibly cleaning the previous output stream.
Our recommendation is to try to use the first method whenever sufficient capacity exists to run two copies of the app and generate two result streams. The first method is much safer — it allows switching back and forth between multiple versions and comparing results between versions, and doesn’t risk losing critical data or introducing errors during the cleanup process.
Kafka Streams by Example
Apache Kafka has two streams APIs: a low-level Processor API and a high-level Streams DSL.
An application that uses the DSL API always starts with using the StreamBuilder to create a processing topology—a directed acyclic graph (DAG) of transformations that are applied to the events in the streams. Then you create a KafkaStreams execution object from the topology. Starting the KafkaStreams object will start multiple threads, each applying the processing topology to events in the stream. The processing will conclude when you close the KafkaStreams object.
public class WordCountExample {
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
KStreamBuilder builder = new KStreamBuilder();
// Define a stream by pointing at the input topic
KStream<String, String> source = builder.stream("wordcount-input");
final Pattern pattern = Pattern.compile("\\W+"); // A non-word character
KStream<Object, String> counts = source
// e.g. "5:I am the hacker." will be transformed to "5:[I, am, the, hacker]"
.flatMapValues(value -> Arrays.asList(pattern.split(value.toLowerCase())))
// e.g. "5:[I, am, the, hacker]" will be transformed to "[{I:I}, {am:am}, {the:the},
// {hacker:hacker}]"
.map((key, value) -> new KeyValue<Object, Object>(value, value))
// e.g. result is "[{I:I}, {am:am}, {hacker:hacker}]"
.filter((key, value) -> (!value.equals("the")))
// e.g. "{I:1, am:1, hacker:1}"
.groupByKey().count("CountStore")
.mapValues(value -> Long.toString(value)).toStream();
counts.to("wordcount-output");
// Run the application!
KafkaStreams streams = new KafkaStreams(builder, props);
streams.start();
// usually the stream application would be running forever,
// in this example we just let it run for some time and stop since the input data is finite.
Thread.sleep(5000L);
streams.close();
}
}
public class StockMarketStatistics {
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "stockstat");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, Constants.BROKER);
props.put(StreamsConfig.KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(StreamsConfig.VALUE_SERDE_CLASS_CONFIG, TradeSerde.class.getName());
// Self-defined Trade object serializer and deserializer
static public final class TradeSerde extends WrapperSerde<Trade> {
public TradeSerde() {
super(new JsonSerializer<Trade>(), new JsonDeserializer<Trade>(Trade.class));
}
}
KStream<TickerWindow, TradeStats> stats = source
// This operation does not do any grouping. Rather, it ensures that the stream of events
// is partitioned based on the record key. Since we wrote the data into a topic with a key and
// didn’t modify the key before calling groupByKey(), the data is still partitioned by its key—so
// this method does noth‐ ing in this case.
.groupByKey()
// The aggregate method will split the stream into overlapping windows, and then apply an aggregate
// method on all the events in the window.
.aggregate(TradeStats::new, (k, v, tradestats) -> tradestats
// The add method of the Tradestats object is used to update the minimum price, number of
// trades, and total prices in the window with the new record.
.add(v),
// (a five-second sliding window every second)
TimeWindows.of(5000).advanceBy(1000), new TradeStatsSerde(),
// Unique name of the state store
"trade-stats-store")
// Turning the table back into a stream of events and replacing the key that contains the entire
// time window definition with our own key that contains just the ticker and the start time of the
// window.
.toStream((key, value) -> new TickerWindow(key.key(), key.window().start()))
// right now the aggregation results include the sum of prices and number of trades. We go over
// these records and use the existing statistics to calculate average price so we can include it in
// the output stream.
.mapValues((trade) -> trade.computeAvgPrice());
stats.to(new TickerWindowSerde(), new TradeStatsSerde(), "stockstats-output");
}
public class TradeStats {
String type;
String ticker;
int countTrades; // tracking count and sum so we can later calculate avg price
double sumPrice;
double minPrice;
double avgPrice;
}
}
public void clickStreamEnrichment() {
// We create a streams objects for the two streams we want to join—clicks and searches
KStream<Integer, PageView> views = builder.stream(Serdes.Integer(), new PageViewSerde(),
Constants.PAGE_VIEW_TOPIC);
KStream<Integer, Search> searches = builder.stream(Serdes.Integer(), new SearchSerde(), Constants.SEARCH_TOPIC);
// Also define a KTable for the user profiles. A KTable is a local cache that is updated through a
// stream of changes.
KTable<Integer, UserProfile> profiles = builder.table(Serdes.Integer(), new ProfileSerde(),
Constants.USER_PROFILE_TOPIC, "profile-store");
// Then we enrich the stream of clicks with user-profile information by joining the stream of events
// with the profile table. In a stream-table join, each event in the stream receives information
// from the cached copy of the profile table. We are doing a left-join, so clicks without a known
// user will be preserved.
KStream<Integer, UserActivity> viewsWithProfile = views.leftJoin(profiles,
(page, profile) -> new UserActivity(profile.getUserID(), profile.getUserName(), profile.getZipcode(),
profile.getInterests(), "", page.getPage()));
// Next, we want to join the click information with searches performed by the same user. This is
// still a left join, but now we are joining two streams, not streaming to a table.
KStream<Integer, UserActivity> userActivityKStream = viewsWithProfile.leftJoin(searches,
// We simply add the search terms to all the matching page views.
(userActivity, search) -> userActivity.updateSearch(search.getSearchTerms()), JoinWindows.of(1000),
Serdes.Integer(), new UserActivitySerde(), new SearchSerde());
}
Kafka Streams
Architecture Review
Building a Topology
Every streams application implements and executes at least one topology. Topology (also called DAG, or directed acyclic graph) is a set of operations and transitions that every event moves through from input to output.
The topology is made up of processors those implement an operation of the data – filter, map, aggregate, etc. There are also source processors, which consume data from a topic and pass it on, and sink processors, which take data from earlier processors and produce it to a topic.
The Streams engine parallelizes execution of a topology by splitting it into tasks. The number of tasks is determined by the Streams engine and depends on the number of partitions in the topics that the application processes. Each task is responsible for a subset of the partitions: the task will subscribe to those partitions and consume events from them. The stream processing tasks can run on multiple threads and multiple servers.
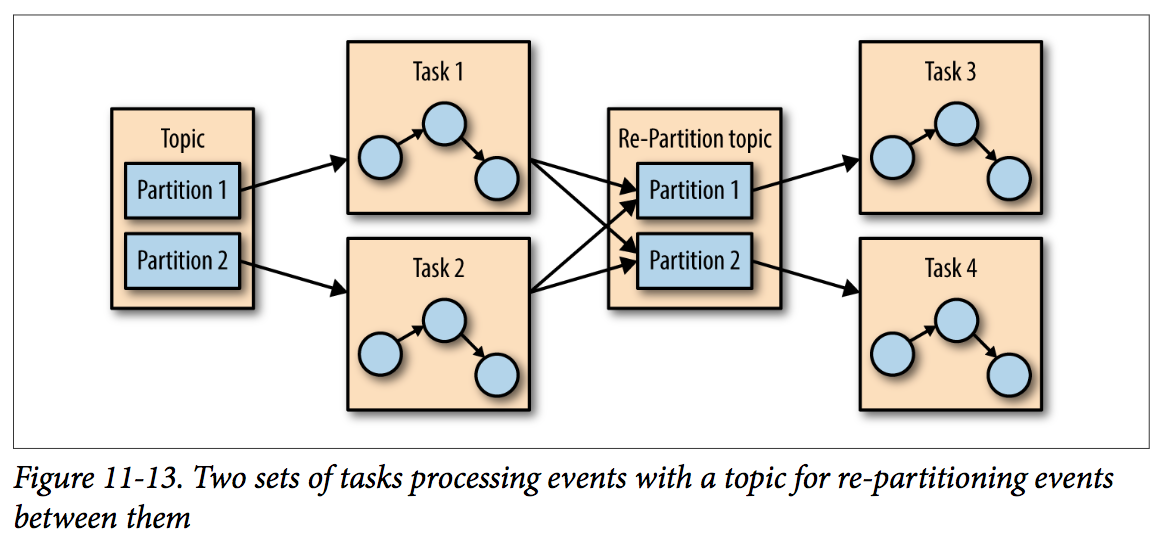
If we need to require results from multiple partitions, like join two streams. Kafka stream will handles this situation by assigning all the partitions needed for one join to the same task so that the task can consume from all the relevant partitions and perform the join independently. This is why Kafka Streams currently requires that all topics that participate in a join operation will have the same number of partitions and be partitioned based on the join key.
Another example of dependencies between tasks is when our application requires repartitioning, So if the application fails and needs to restart, it can look up its last position in the stream from Kafka and continue its processing from the last offset it committed before failing; If the local state store is lost, the streams application can always re-create it from the change log it stores in Kafka; If a task failed but there are threads or other instances of the streams application that are active, the task will restart on one of the available threads.