Understanding Cloud Native Concepts
Discuss each of following concepts with regard to how they each help deliver on the promises of cloud-native: speed, safety, and scale:
- Powered by disposable infrastructure
- Composed of bounded, isolated components
- Scales globally
- Embraces disposable architecture
- Leverages value-added cloud services
- Welcomes polyglot cloud
- Empowers self-sufficient, full-stack teams
- Drives cultural change
Cloud-native is more than architecting and optimizing to take advantage of the cloud. It is an entirely different way of thinking and reasoning about software architecture and development practices. Cloud-native breaks free of monolithic thinking to empower self-sufficient teams that continuously deliver innovation with confidence.
The Anatomy of Cloud Native Systems
-
Reactive Manifesto: A system should be responsive, resilient, elastic, and message-driven.
-
At the heart of any database is the transaction log. The transaction log is an append-only structure that records all the events (insert, update, and delete) that change the state of the data. The logs can be replayed to recreate the current state of the tables if need be. The database also manages indexes and materialized views, also caches query results, but they are all another copy of the data. Our objective is to take all this processing and turn it inside out, so that we can spread this processing across the cloud, to achieve massive scale and sufficient isolation. The message-driven (event streaming) is the externalized transaction log.
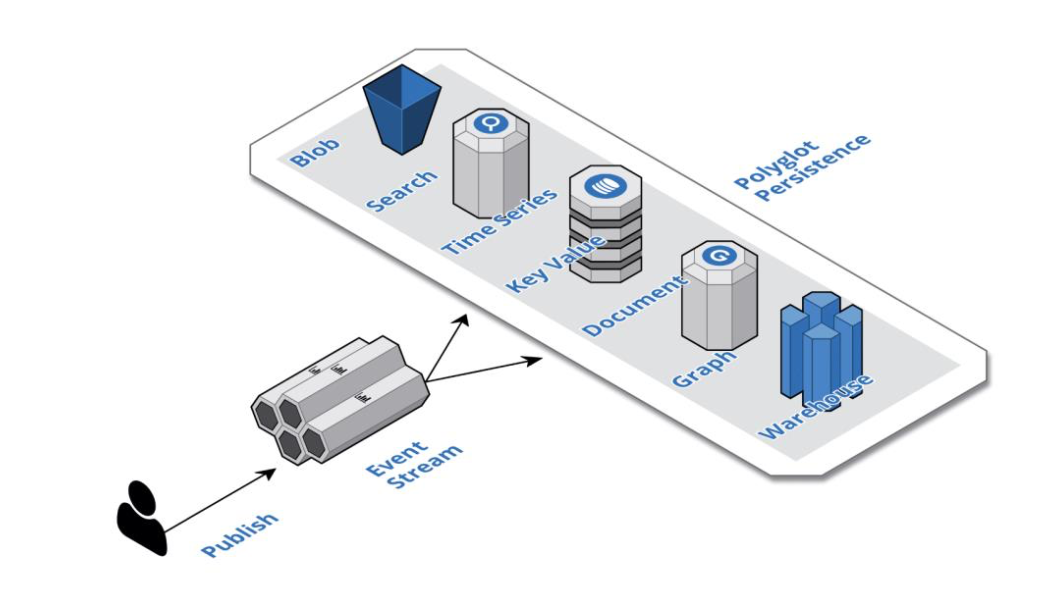
-
Event streaming is our message-driven, publish and subscribe mechanism for asynchronous inter-component communication. Event streams have a single responsibility, to receive and durably store events, lots of events, at massive scale. An event stream is an append-only, sharded database, that maintains an ordered log of events and scales horizontally to accommodate massive volumes. Each hand-off in the flow of events through the system is implemented transactionally by the smart endpoints (this is components) and their supporting architecture to achieve eventual consistency. The downstream components consume these events to trigger their behavior and cache pertinent information in materialized views. These materialized views make components responsive by providing a dedicated cache that is continuously warmed and available in local storage.
-
Eventual consistency allows for reduced contention and increased throughput because resources are not locked over the courses of these logical transactions. This means that different logical transactions can potentially interlace and update the same resources. Therefore, we cannot simply rollback the state of a resource to the state before a specific logical transaction started. We must take into account all the additional updates that have been layered on top of the updates of the specific logic transaction that must be reversed. With this in mind, we need to maintain an audit trail of the series of updates that have interlaced to bring a resource to its current state. Reversing the effects of a specific update should be accomplished by another properly calculated update that is also account for in the audit trail. As always these updates must be idempotent. In some cases, delegating the reversal of a transaction to a manual activity may be perfectly legitimate.
-
Polyglot persistence uses many different types of databases. Each component in the system uses the right storage technology for the job and often multiple kinds of databases per component. such as key-value stores, document stores, search engines, graph databases, time series databases, blob or object storage, mobile offline-first databases, column-oriented data warehouses, and append-only streams. For instance, The Account component is responsible for managing a customer’s profile, preferences, shopping cart, and order history, also recent orders are stored in an offline-first, mobile database in local storage.
-
Cloud native database is NOT a monolithic, shared database model. They are purchased, provisioned, and tuned one table at a time. This means that one table can be a document store, another table is a search index, and another table is blob storage, and so forth. They all operate across availability zones as a matter of course and more and more of these offerings have turnkey regional replication.
-
Cloud Native Patterns
- Foundation patterns: Cloud-Native Databases per Component; Event Streaming; Event Sourcing; Data Lake; Stream Circuit Breaker; Trilateral API.
- Boundary patterns: API Gateway, Command Query Responsibility Segregation; Offline-First Database; Backend For Frontend; External Service Gateway.
- Control Pattern: Event Collaboration; Event Orchestration; Saga
Foundation Patterns
-
Cloud-Native Database per Component
Employ multiple database types within a component, as needed, to match the component’s workload characteristics. Choose the database type, such as document store, blob storage, or search on a table-by-table basis. Use the change-data-capture (CDC) and life cycle management features and react to the emitted events to trigger intro-component processing logic.
-
Event Streaming
Leverage a fully managed streaming service to implement all inter-component communication asynchronously, whereby upstream components delegate processing to downstream components by publishing domain events that are consumed downstream. Define a standard event envelope format so that all the following consumers can handle events in a consistent manner. e.g. all events could have the fields: id, type, timestamp, and tags.
-
Event Sourcing
Communicate and persist the change in state of domain entities as a series of atomically produced immutable domain events. Those events must performance one and only one atomic write operation against a single source, either a stream or a cloud-native database.
-
Data Lake
Collect, store and index all events in their raw format in perpetuity with complete fidelity and high durability to support auditing, replay, and analytics. These collecting consumers should be optimized to store the events in batches with high throughput.
-
Stream Circuit Breaker
Delete events with unrecoverable errors to another component for handling so that they do not block legitimate events from processing. Publish these errors as fault events, along with the effected events and the stream processor info, so that the events can be resubmitted. Monitor and alert on these fault events so that the team can react in a timely manner.
-
Trilateral API
Publish multiple interfaces for each component: a synchronous API for processing commands and queries, an asynchronous API for publishing events as the state of the component changes, and/or an asynchronous API for consuming the events emitted by other components.
Boundary Patterns
-
API Gateway
Provides a fully managed, global scale perimeter around the system that allows self-sufficient, full-stack teams to focus on their value proposition. Use the cloud provider’s CDN and WAF (Web Application Firewall) for additional security features as needed.
-
Command Query Responsibility Segregation
Downstream components consume the events and maintain their own materialized views that are optimized for each component’s specific needs. Each component employs persistence and chooses the appropriate cloud-native database type for each view. So queries will continue to return results from the materialized views even the upstream is unavailable.
-
Offline-first Database
Persist user data in local storage and synchronize with the cloud when connected so that users always access the latest known information.
-
Backend For Frontend
To fully empower self-sufficient, full-stack teams, a single team needs to own a frontend feature and its supporting backend, and own the materialized views that both shield the component from and integrate it with upstream components.
Modern websites are built as a collection of multiple, mobile-first, single page applications that are delivered from the CDN.
-
External Service Gateway
Integrate with external systems by encapsulating the inbound and outbound inter-system communication within a bounded isolated component to provide an anti-corruption layer that acts as a bridge to exchange events between the systems.
The transformed event enables the possibility of replacing an external system with another external system as needed or even supporting multiple external systems for the same functionality.
Control Patterns
-
Event Collaboration
Command Query Responsibility Segregation (CQRS) pattern is leveraged to replicate data from upstream components to avoid performing non-resilient, synchronous inter-component communication to retrieve needed informations.
Publish domain events to trigger downstream commands and create a reactive chain of collaboration across multiple components. This cycle repeats through as many steps as are necessary to complete the activity. The cycle can fan-out to perform steps in parallel and then fan-in as well.
For example, the customer completes and submits the order, and then the reservation must be confirmed, followed by charging the customer’s credit card, and finally sending an email confirmation to the customer.
-
Event Orchestration
Create a component for each business process to act as a mediator between the collaborator components and orchestrate the collaboration flow across those components. Each component defines the events it will consume and publish independently of any business processes. The mediator maps and translates the published events of upstream components to the consumed events of downstream components. These mappings and translations are encapsulated in the mediator as a set of rules, which define the transitions in the collaboration flow.
As intended, the mediator components is essentially a dumb pipe that delegates the business logic of each step to the collaborator components. It is only responsible for the transition logic.
-
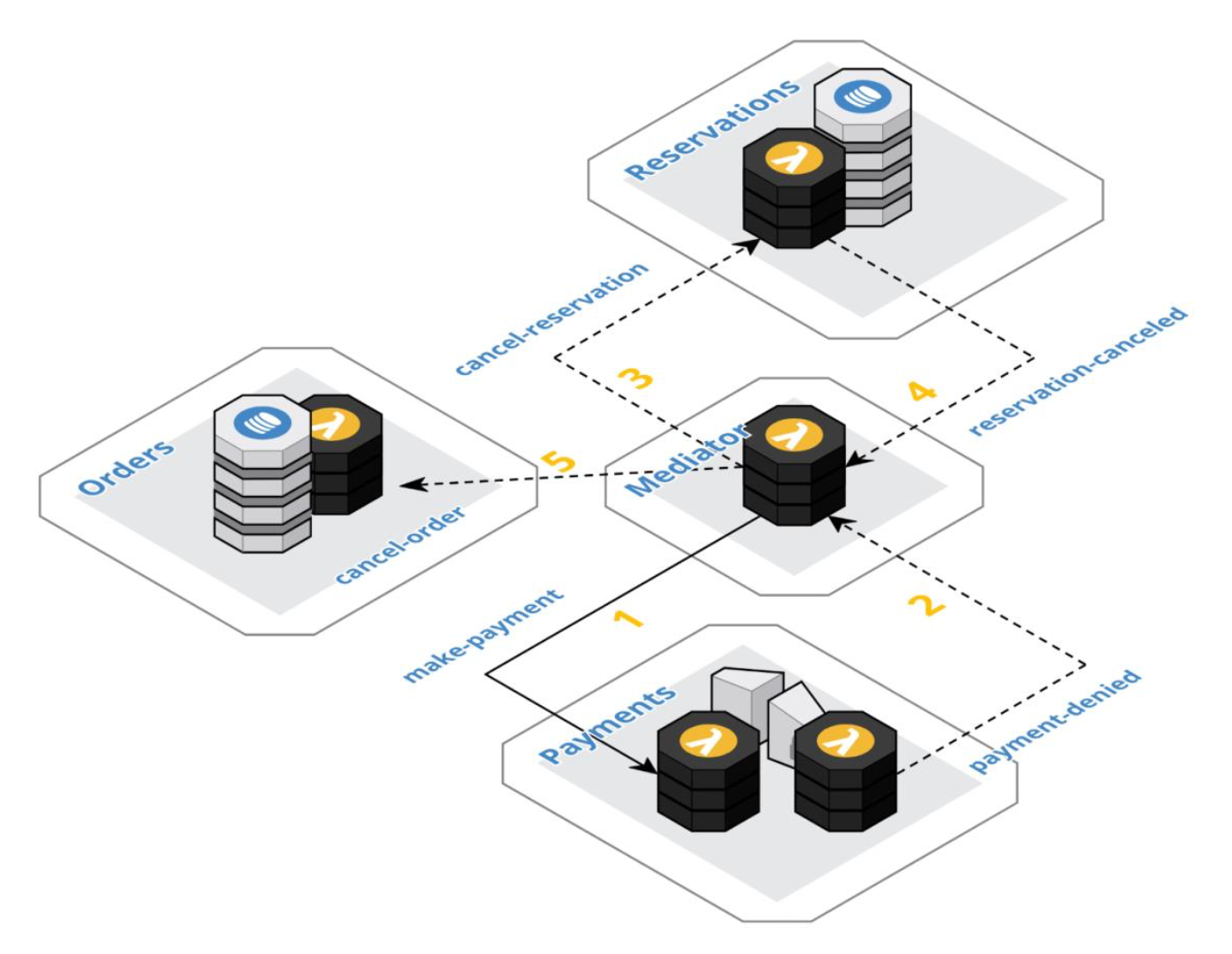
Saga
Use compensating transactions to undo changes in a multi-step business process. Upstream components will publish domain events as they complete their steps to move a business process forward. A downstream component will publish an appropriate violation event when its business rules are violated to inform the upstream components that the process cannot process forward to completion. The upstream components react to the violation event by performing compensating transactions to undo the changes of the previous steps in the collaboration. The upstream components will, in turn, produce their own domain events to indicate the reversal has occurred, which may in turn trigger additional compensations. This cycle will continue until the system is eventually consistent.
It is important to distinguish between business rule violations and error handling. The Stream Circuit Breaker pattern is responsible for error handling, while the Saga pattern is responsible for business rule violations.
Deployment
Shift deployments all the way to the left, and leverage dark launches to help enable teams to continuously deploy changes to production and continuously deliver innovation to customers with confidence.
-
Decoupling deployment from release
With cloud-native, we treat the two as interrelated parallel threads by decoupling deployment from release. A deployment is just the technical act of deploying a small, focused, and controlled change to a single bounded isolated component; whereas a release is a human act of delivering (this is enabling) a capability for the consumer. The two work in tandem.
-
Multi-level roadmaps
Perform deployments much more frequently according to Release roadmaps, Story mapping or Deployment roadmaps. However we must be very deliberate about each deployment. For example the order in which related changes are deployed to multiple components may be very important.
-
Task branch workflow
Each task is a self-contained unit of work that will ultimately be deployed to production. This unit of work includes coding the functionality and tests, performing code review, executing the tests, testing the deployment, deploying to production and asserting the stability of the system. Git Pull/Merge request is a choice to govern this process.
-
Modern deployment pipelines
The deployment pipeline is governed by a Git pull request which is orchestrated by multiple tools. A modern CI/CD tool controls the overall flow, node package manager (npm) controls the individual steps, the cloud provider’s infrastructure-as-code service provisions the cloud resources, and the Serverless Framework provides an important abstraction layer for the infrastructure-as-code service or managing Function-as-a-Service projects.
-
Zero-downtime deployment
To achieve this, the system components must be stateless, since a component may be changed out in the middle of user sessions. A new component must also be backwards compatible because it is not possible to change out all the components at the exact same time.
The blue-green deployment is to maintain two identical infrastructure environments (a blue cluster and a green cluster); The canary deployment approach improves on the blue-green approach by routing only a portion of users to the new version.
-
Multi-regional deployment
To implement regional deployment, we simply add an NPM script and a CI job for each region. The regional deployment jobs could be triggered when a region-specific tag is applied to the master branch.
-
Feature flags
A feature flag provides the ability to hide, enable, or disable a feature at runtime. The changes in each deployment are effectively turned off until they are explicitly enabled.
-
Versioning
We are continuously deploying small batch sizes to production, staggered across multiple regions, and leveraging feature flags to hid new capabilities until they are ready for consumption. When new features are ready for consumption, we enable them incrementally for specific target audiences to elicit feedback. We may event implement A/B testing based on feature flags to test user reactions to different versions of a feature.
A deployment roadmap for a database schema change
- Deploy the new database alongside the existing database.
- Implement a new listener to consume events and populate the new database.
- Implement a feature flag in the BFF logic to flip flip between data sources.
- Replay past events from the data lake to seed the new database. This step could be protracted if there is a large amount of historical data.
- Deploy the change to switch to the new database.
- Remove the old database and its listener.
-
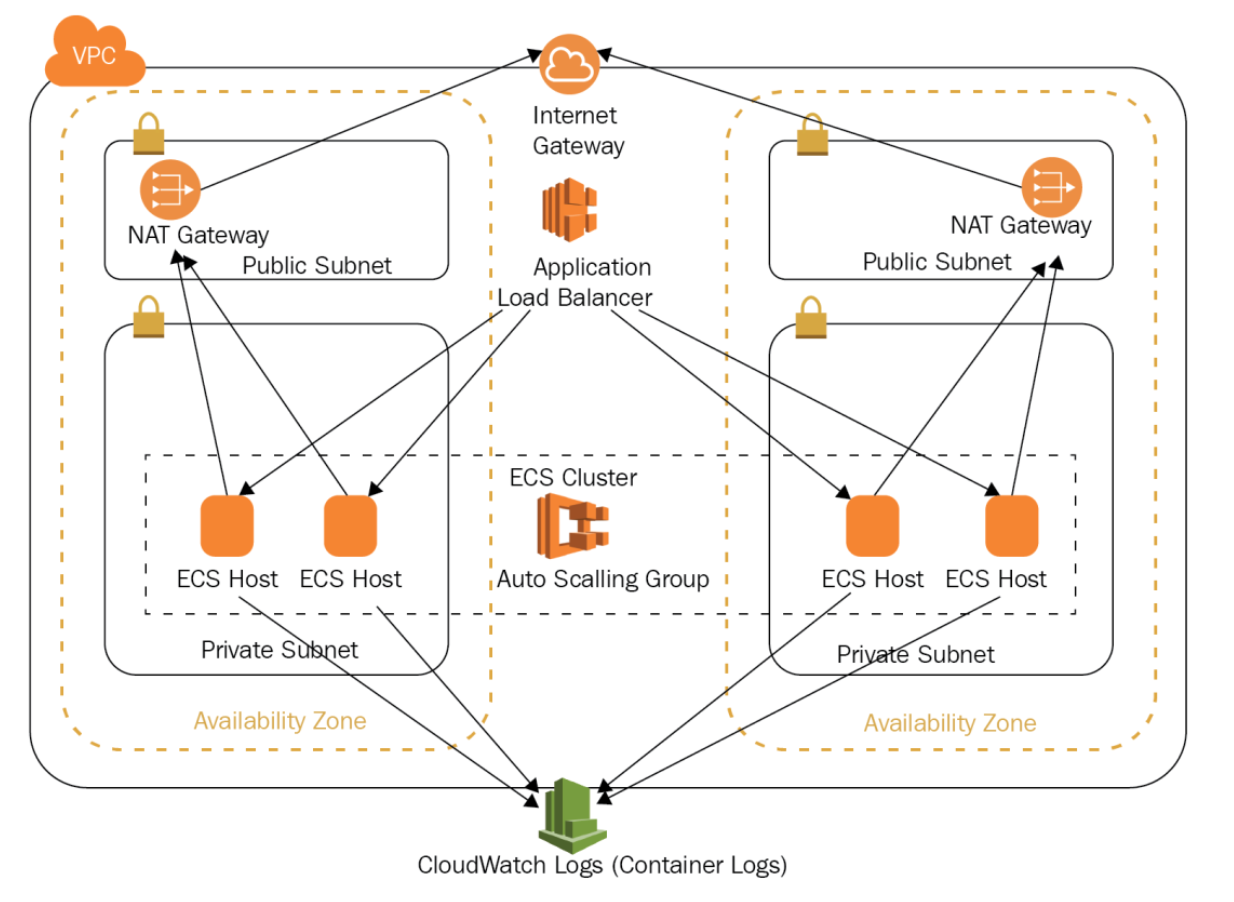
Trilateral API per containers
Function-as-a-Service is a nature fit for cloud-native systems. They integrate seamlessly with a cloud provider’s API gateway service, streaming service, and cloud-native database streams.
The following diagram provides an example of the various services involved in running an AWS Elastic Container Service (ESC) cluster.
Testing
We will shift testing all the way to the left and weave it into the CI/CD pipeline to help enable teams to continuously deploy changes to production and delivery innovation to customers with confidence.
-
Shifting testing to the left
Testing is no longer a phase – it is an integral part of the cloud-native product delivery pipeline. Testing is no longer a job title – it is a team effort.
-
Test engineering
Test engineering largely revolves around architecting a shared understanding of the system as a whole. Supports the critical responsibility of asserting the health of the system in production.
-
Isolated Testing
The isolation of external resources is accomplished via test doubles. For unit testing and component testing, you can use the mocking library that is best suited to your project. Also need to isolate the tests in relation to time.
-
Transitive Testing
We want small batch sizes and frequent deployments along with full integration and end-to-end testing. We want the stability of isolated testing along with the confidence that components fit together properly.
VCR libraries provide test doubles (mocks) that are able to record and play back the request and response payloads during integration testing. Contract testing ensures that a component has not broken its contract with its consumers. end-to-end testing asserts whether a specific flow of an application behaves as expected from start to finish.
Given a well-crafted end-to-end test case scenario, multiple teams can coordinate to chain together a series of integration and contract test interactions to create an arbitrarily long end-to-end test built entirely of isolated tests.
The devil is always in the details.
-
Manual Testing
We looked at how we need to shift testing to the left and make it an integral part of the deployment pipeline. Each task branch workflow implements just enough code to accomplish the task and all that code is completely tested. All automated testing is performed within the pipeline to ensure that we fail fast, with a tight feedback loop. This necessitates testing components in isolation to account for the complexities of testing distributed systems. We leverage transitive testing techniques to accomplish end-to-end testing as an aggregation of multiple isolated tests. Test automation has transformed the traditional tester role into a test-engineering discipline. However, we still need to perform manual exploratory testing to help ensure that we are building the correct system.
Testing framework: Mocha + Selenium + Sauce Labs.
Monitoring
-
Shifting testing to the right
To be proactive, we must shift some testing all the way to the right into production. We must identify the system’s key performance indicators and actively monitor and alert on these values when they deviate from the norm. We cannot rely solely on real user activity. We need to synthesize traffic such that the system continuously emits a signal to monitor. Our bounded isolated components must be observable. They must emit sufficient information to support the key performance indicators and facilitate root cause analysis. We must avoid alert fatigue so that teams can trust the alerts and jump into action.
-
Key performance indicators
The cloud-native systems will produce many observable signals and symptoms, some of them are more important and more valuable than others. These are the system’s key performance indicators.
-
TestOps
-
Real and synthetic traffic
We certainly want to monitor real user traffic and fully understand the quality of their user experience. We also need to continuously synthesize predictable (fake/distinguished) traffic predictable traffic to sufficiently fill the gaps in real traffic to support asserting the health of the system.
-
Observability
Collecting data may be cheap, but we need guidelines to help us turn this mountain of data into valuable information.
The first step is to take measurements of the important aspects of the component, a.k.a metric. A metric is a time series of data points (gauge, count, or histogram [count, max, min, p95, median]) that we can monitor, aggregate, slice, and dice to observe the inner workings of the component.
There are several telemetry approaches for collecting the metrics. We can classify these approaches as cloud provided, agents, and logs.
Structured logging is a natural approach to recording custom metrics when using function-as-a-service. Functions are instrumented by recording structured log statements for counters, gauges, and histograms. The monitoring system continuously processes the centralized logs and extracts the structured statements. This processing is able to calculate the statistical distributions for the histograms from the individual statements.
-
Alerting
Alerting is a double-edged sword. The classic problem with monitoring is alert fatigue, Team receiving far too many alerts will eventually stop paying attention to the alerts. Team can treat different severity alerts accordingly.
-
Focusing on mean team to recovery
Teams should create a dashboard to display all the work metrics for each component. Once we have been alerted to a symptom we can investigate the root cause in a methodical manner. For stream processors, it is often useful to observe the problem in action. Once a solution is identified, it is usually easier and just as fast or faster to roll-forward.
-
Performance tuning
Traditional resources are cluster-based. You allocate a cluster size and you eventually determine, through testing or production usage, how much throughput can be sustained on the chosen cluster size.
Value-added cloud services are typically provisioned based on the desired throughput, such as an API Gateway or a function-as-a-service, implicitly scale to meet demand but do so within an upper throttling limit.
As always, teams need to implement all synchronous API calls to handle throttling with retry and exponential back-off logic.
A typical example is a high traffic read operation. Adding a short cache-control header to the response would cause the request to be frequently handled by the CDN, thus removing the latency and cost of API gateway and function invocations and the increased database read capacity. Alternatively, if the response changes very infrequently, then storing the JSON in blob storage and serving it directly out of the CDN results in a significant reduction in cost and delivers consistently low latency, not just when there is a cache hit.
High volume stream processors will likely be candidates for performance tuning. The iterator age of the function will be the lading indicator. First, increasing the shard count could spread the load across multiple instances of the processor, so long as the partition key is well distributed. Next, an increase in batch size and/or the memory allocation could allow the processor to more efficiently process the load.
The bottleneck could also be related to the utilization or saturation of the target resources. When invoking a cloud-native database, we want to maximize utilization by optimizing the request batch size to minimize the number of network requests while also optimizing the number of parallel requests to maximize the use of asynchronous non-blocking IO. The optimal combination of batch size and parallel requests can be added to rate limit the flow within the allocated capacity.
Security
“There is no way I can build a system as secure as I can in the cloud, because I simply do not have the resources to do so.”
-
Shared responsibility model
Security in the cloud is based on a shared responsibility model, whereby the cloud provider and the customer work together to provide system security. Generally speaking, below a certain line in the architecture is the responsibility of the cloud provider and above that line is the responsibility of the customer. The aim is to draw the line high enough such that customer is focused on protecting the confidentiality, integrity and availability of the data and not the infrastructure itself.
-
Security by design
Security-by-design should start well before the story level. As we architect the feature roadmap we need to classify the sensitivity level of each feature and its individual stories. The security requirements are continuously and incrementally designed and fully automated.
-
Account as code
Once we have designed the architecture of our account hierarchy and topology, we need to codify the implementation of each account. Also grant the root user, the monitoring system, and the CI/CD pipeline access to the account. Next, we need to grant user privileges. Least privileged access and separation of duties are the fundamental principles, the definitions of groups and policies are treated as code too.
-
Defense in depth
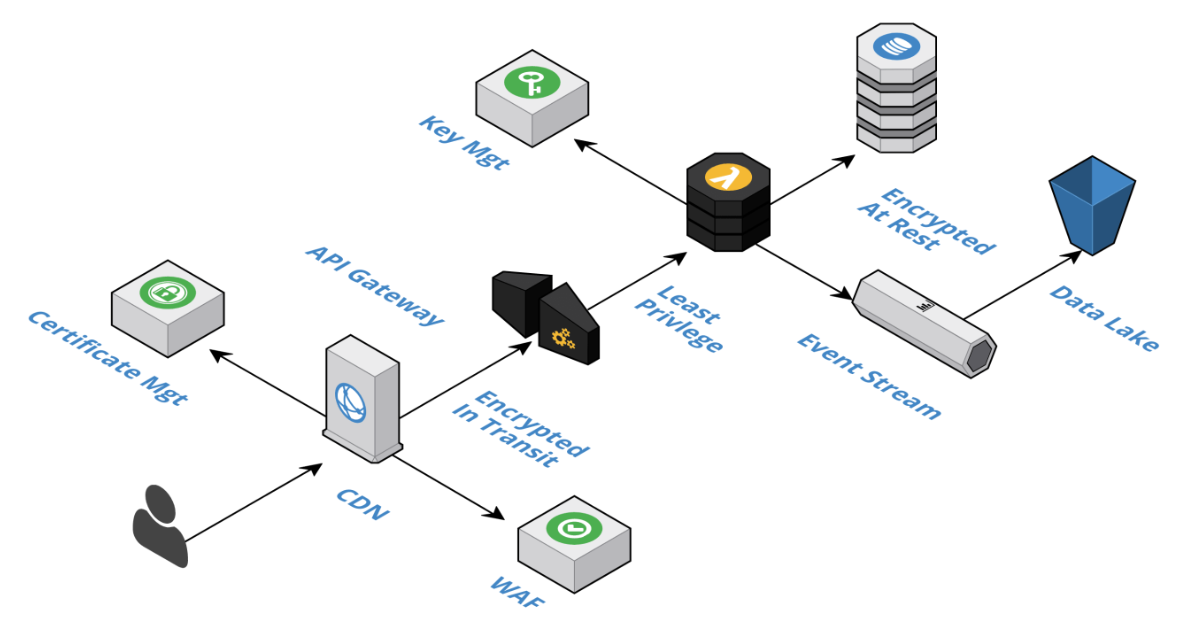
Edge layer: Cloud providers have vast and expansive capabilities spread around the globe. It is recommended to route all traffic, PUT, POST, DELETE, GET, and so forth, through CDN, to minimize the attack surface of a cloud-native system, like network level DDoS attack and encryption of data in transit. All traffic flowing through the CDN is filtered against the rule set of the WAF (Web Application Firewall), such as SQL injection, cross-site scripting, bad actors.
Component layer: Has many different security responsibilities, such as DDoS protection, Throttling, Autoscaling, Monitoring and Altering (through API Gateway); Also manage least privileged access and encryption of data.
Data layer: Securing the data layer is more difficult because the requirements are domain specific and thus require input from domain experts, to classify the sensitivity level of the different domain entities and their individual data elements.
-
Encryption
Based on the sensitivity level of domain data, teams need design the proper levels of obfuscation into their components. Cloud providers offer a certificate management service. Encrypting data at rest is a much more complicated problem space than encrypting data in transit. Teams can use the cloud provider’s key management service to encrypt sensitive fields using an approach called envelope encryption, which is the process of encrypting one key with another key.
Tokenization works for some types of data. A token is a generated value that replaces and references the real value. It can only be used to look up the real value. such as a tokenized credit card number is 4111-XXXX-YYYY-1111.
-
Disaster recovery
Code Spaces perished so that we could learn from their mistakes.
It highlights the need to be vigilant with your access keys.
Don’t ward off a malicious attach or a catastrophic human error with automation across regions.
Backup the data in different accounts and different regions.
-
Application security
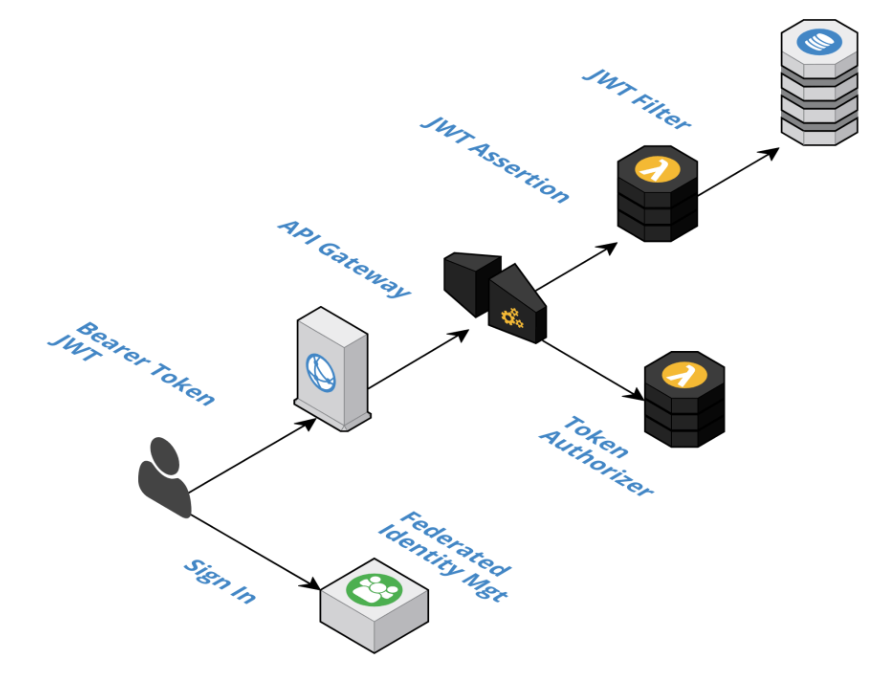
Federated identity management supports: OAuth2.0, Open ID Connect and JSON Web Token (JWT).
Your frontend code should redirect to the third-party sign-in page when it doesn’t have a validate JWT token. Once authenticated, the user is redirected back to your application with a JWT token that you securely save in local storage so that it can be passed along on requests to BFF components through an API gateway.
The API gateway acts as a barrier at the edge of the system and is responsible for verifying the signature of the bearer token. If you are using the federated identity management service then the turnkey integration with the API gateway will likely be all that your need to secure your API at this layer.
The UUID or username of the authenticated user should be used to stamp any database update or event for auditing purposes. The claims/entitlements in the token can be used for conditional control flow or to assert business level validations.
-
Regulatory compliance
Compliance with the many security certifications, regulations, and frameworks, such as SOC, PCI, and HIPAA, is of extreme importance to cloud providers because it is important to cloud consumers.
Value Focused Migration
-
Risk mitigation
Cloud-native is the antithesis of these previous big-bang migrations. The transformation happens incrementally with the legacy system and the cloud-native system co-existing and working in tandem to accomplish the mission of the overall system until the legacy system is ultimately decommissioned.
Anti-pattern – Lift and Shift is essentially a lateral move where the system is moved out of the data center as-is and into the cloud. This approach will not take advantage of any of the benefits of the cloud, such as Autoscaling, Self-sufficient. Typically, leaving the legacy system in the data center and building the cloud-native system around it is more cost effective.
Anti-pattern – synchronous anti-corruption layer will couple the cloud-native system to the performance, scalability, and availability limits of the legacy system. Instead, we need to leverage an asynchronous anti-corruption layer, such as the External Service Gateway in combination with Common Query Responsibility Segregation (CQRS) pattern.
-
Strangler pattern
Leaves the legacy system in place for as long as necessary, while focus on addressing pain points, new features with the new cloud-native components, continuously deliver a more and more comprehensive solution without the need to address every edge case from the very beginning.
-
Bi-directional synchronization and latching
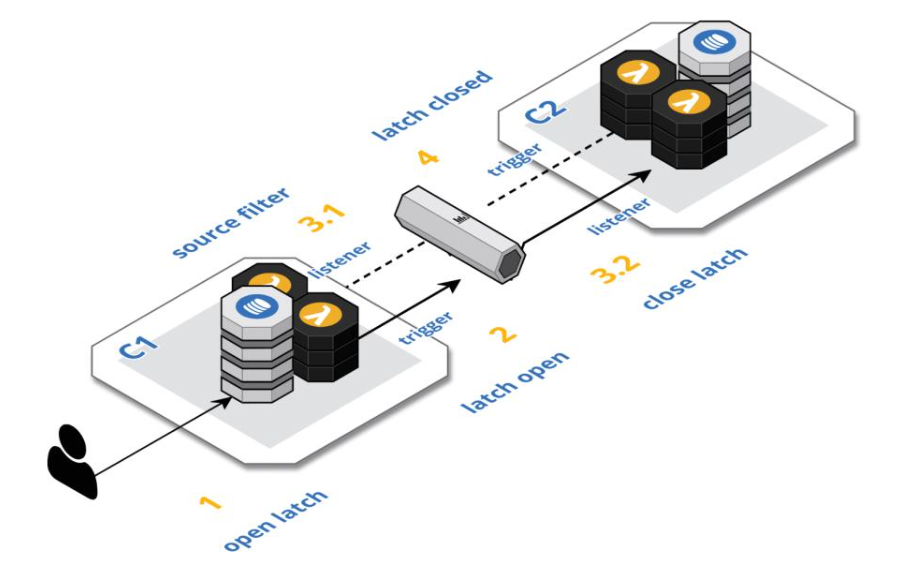
Lets walk through the scenario depicted in the preceding diagram for cloud-native C1 and C2:
- A user interact with C1 and saved the results in database. A latch property on the object set to open.
- Saving the data will trigger C1’s outbound stream processor which inspects the latch value and continue to publish the event of type X to the event stream because the latch is open.
- Both C1 and C2 are listing for event type X.
- C1 will filter out all events produced by itself by evaluating the source tag is not equal to C1.
- C2 filters out all its own events as well, but it will consume this event and saves it to its database, also set the latch to closed.
- Saving the data in step 3.2 triggers C2’s outbound stream processor, which inspects the latch value and short-circuits its processing because the latch is closed.
Regarding the legacy system uses a relational database. Either use the legacy system to produces events to cloud-native domain. Or we can add triggers to capture the insert, update, and delete events and write the contents of the events to a staging table that will be polled by the anti-corruption layer.
-
Empowering self-sufficient, full-stack teams
Cloud-native is a paradigm shift that requires rewriting our engineering brains. Empower self-sufficient, full-stack teams to define the migration roadmap, implement our cloud-native development practices, and establish the cloud-native foundational components.
-
Evolutionary architecture
This aspect of cloud-native evolutionary architecture is largely driven by the human factors of lean thinking that is facilitated by disposable infrastructure, value-added cloud services, and disposable architecture.
-
Welcome polyglot cloud
Cloud-native is an entirely different way of thinking and reasoning about software systems.
As you can see, there is really no reason not to welcome polyglot cloud. :)