What is Hadoop?
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
The project includes these modules:
- Hadoop Common: The common utilities that support the other Hadoop modules.
- Hadoop Distributed File System (HDFS): A distributed file system that provides high-throughput access to application data.
- Hadoop YARN (Yet Another Resource Negotiator): A framework for job scheduling and cluster resource management.
- Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
RDBMS compared to MapReduce
| Item | RDBMS | MapReduce |
|---|---|---|
| Data Size | Gigabytes | Petabytes |
| Access | Interactive and batch | Batch |
| Updates | Read and write many times | Write once, read many times |
| Transactions | ACID | None |
| Structure | Schema-on-write | Schema-on-read |
| Integrity | High | Low |
| Scaling | Nonlinear | Linear |
Part I: Hadoop Fundamentals
Set Up a Single Node Hadoop
etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/Users/lchen/bigdata/data/hadoop</value>
</property>
</configuration>
A Weather MapReduce Sample
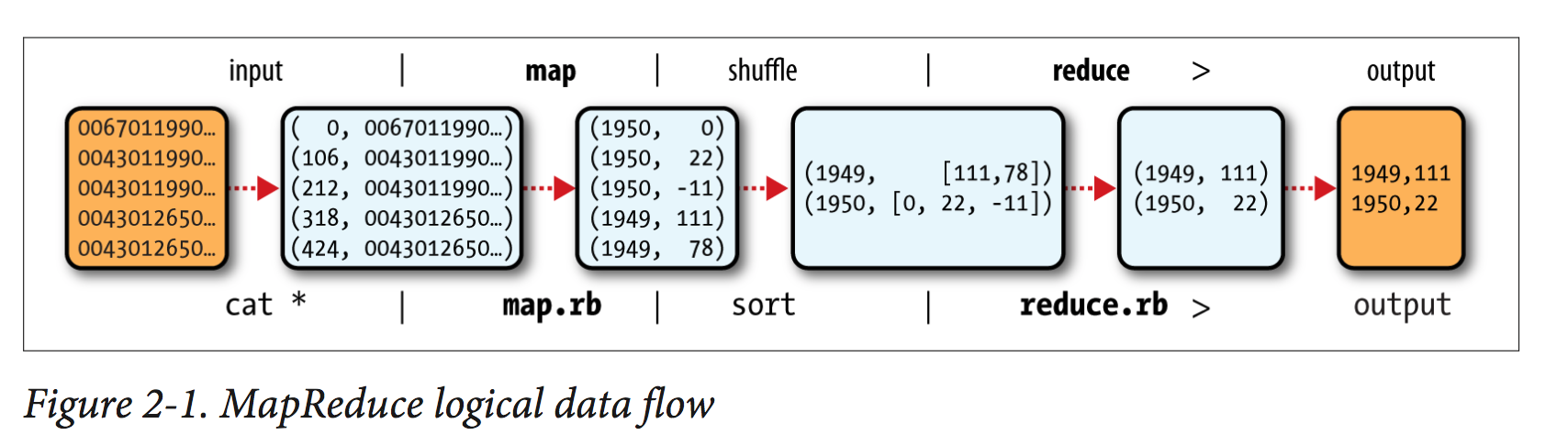
When we run this job as below on a Hadoop cluster, we will package the code into a JAR file (which Hadoop will distribute around the cluster). Rather than explicitly specifying the name of the JAR file, we can pass a class in the Job’s setJarByClass() method, which Hadoop will use to locate the relevant JAR file by looking for the JAR file containing this class.
public class MaxTemperature {
public class MaxTemperatureMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private static final int MISSING = 9999;
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String year = line.substring(15, 19);
int airTemperature;
if (line.charAt(87) == '+') { // parseInt doesn't like leading plus signs
airTemperature = Integer.parseInt(line.substring(88, 92));
} else {
airTemperature = Integer.parseInt(line.substring(87, 92));
}
String quality = line.substring(92, 93);
if (airTemperature != MISSING && quality.matches("[01459]")) {
context.write(new Text(year), new IntWritable(airTemperature));
}
}
}
public class MaxTemperatureReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int maxValue = Integer.MIN_VALUE;
for (IntWritable value : values) {
maxValue = Math.max(maxValue, value.get());
}
context.write(key, new IntWritable(maxValue));
}
}
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: MaxTemperature <input path> <output path>");
System.exit(-1);
}
Job job = new Job();
job.setJarByClass(MaxTemperature.class);
job.setJobName("Max temperature");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// use compression
FileOutputFormat.setCompressOutput(job, true);
FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
job.setMapperClass(MaxTemperatureMapper.class);
job.setCombinerClass(MaxTemperatureReducer.class); // optional
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Scaling Out (Data Flow)
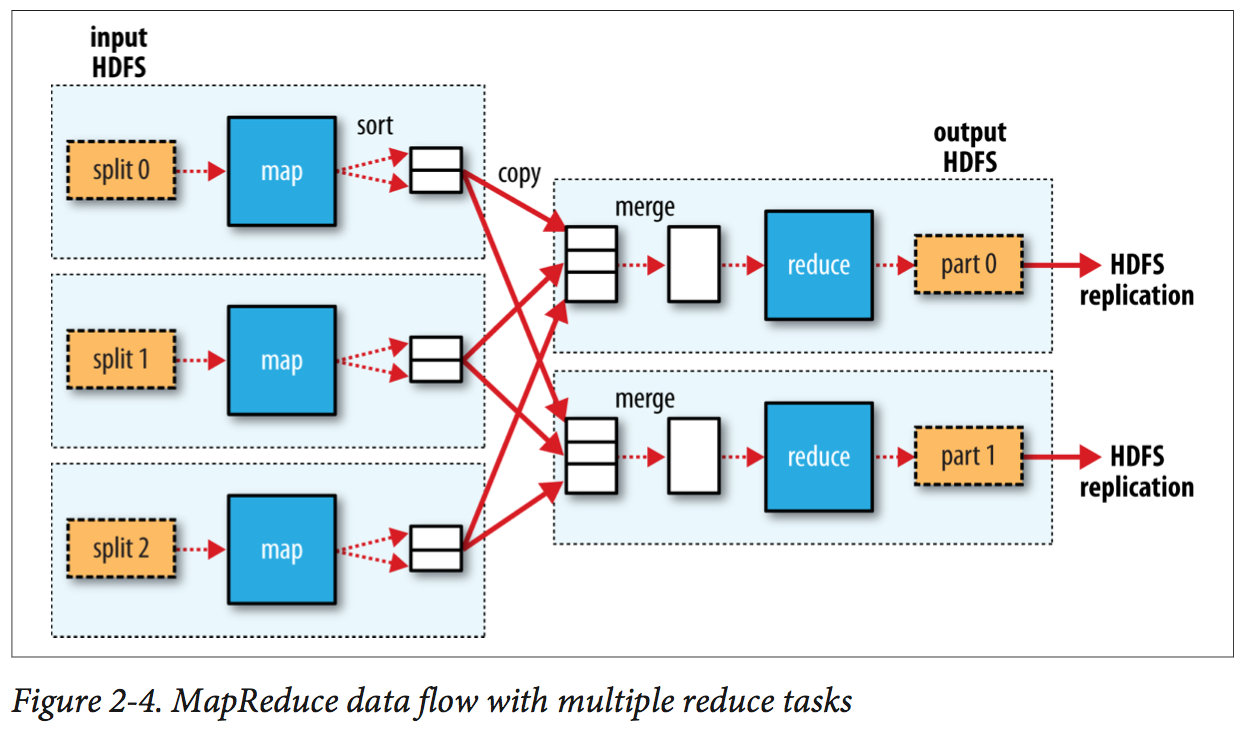
A MapReduce job is a unit of work that the client wants to be performed: it consists of the input data, the MapReduce program, and configuration information. Hadoop runs the job by dividing it into tasks, of which there are two types: map tasks and reduce tasks. The tasks are scheduled using YARN and run on nodes in the cluster. If a task fails, it will be automatically rescheduled to run on a different node.
Hadoop divides the input to a MapReduce job into fixed-size pieces called input splits, or just splits. Hadoop creates one map task for each split, which runs the user-defined map function for each record in the split. For most jobs, a good split size tends to be the size of an HDFS block, which is 128 MB by default (changeable). Because a block is the largest size of input that can be guaranteed to be stored on a single node.
Map tasks write their output to the local disk, not to HDFS since Map output is intermediate output: it’s processed by reduce tasks to produce the final output, and once the job is complete, the map output can be thrown away or re-created. So, storing it in HDFS with replication would be overkill. While the output of the reduce is normally stored in HDFS for reliability.
To minimize the data transferred between map and reduce tasks, Hadoop allows the user to specify a combiner function to be run on the map output, and the combiner function’s output forms the input to the reduce function. Hadoop does not guarantee of how many times it will call it for a particular map output record.
max(0, 20, 10, 25, 15) = max(max(0, 20, 10), max(25, 15)) = max(20, 25) = 25
Hadoop Distributed Filesystem
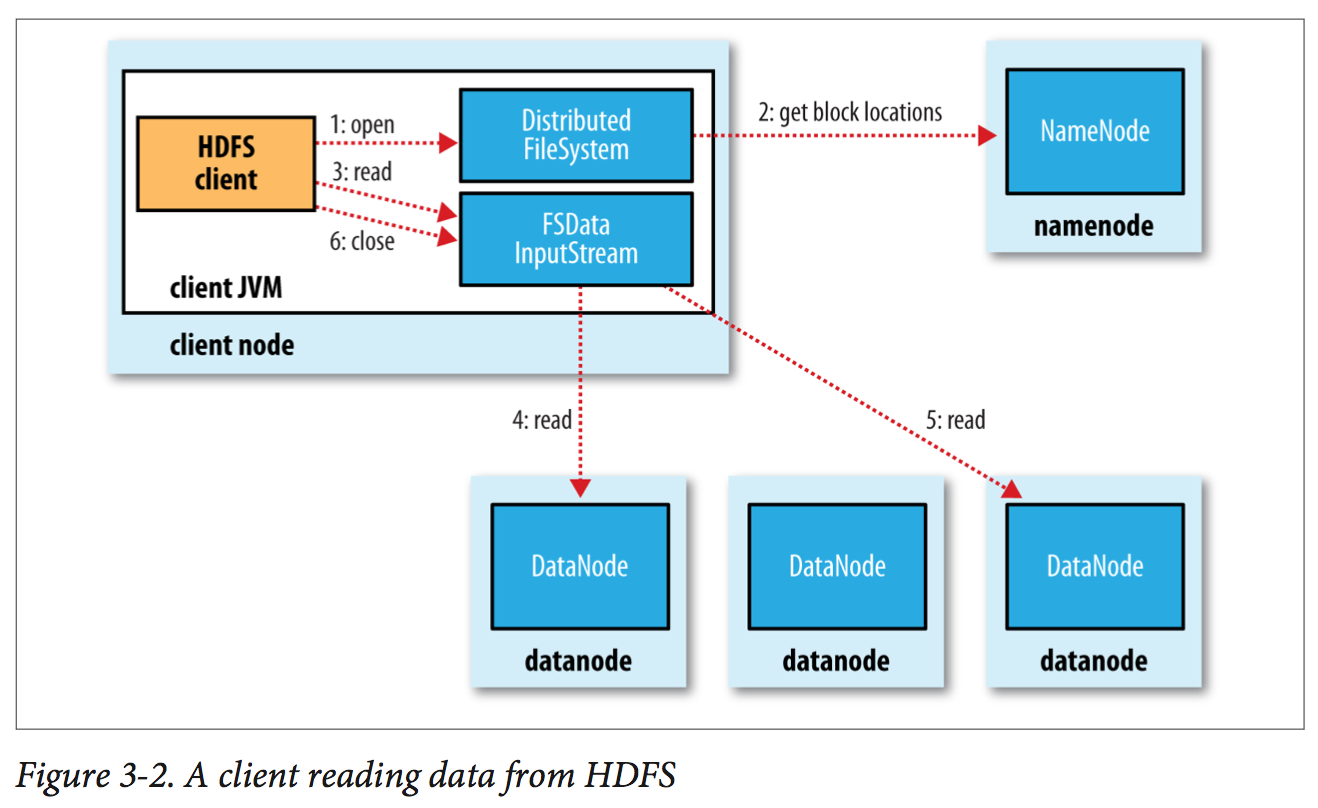
An HDFS cluster has two types of nodes operating in a master−worker pattern: a namenode (the master) and a number of datanodes (workers). The namenode manages the filesystem namespace. It maintains the filesystem tree and the metadata for all the files, blocks and directories in the tree. Datanodes are the workhorses of the filesystem. They store and retrieve blocks when they are told to (by clients or the namenode), and they report back to the namenode periodically with lists of blocks that they are storing.
Failover and fencing The default implementation uses ZooKeeper to ensure that only one namenode is active. Each namenode runs a lightweight failover controller process to monitor for failures (using a simple heartbeating mechanism). If the active namenode fails, the standby can take over very quickly (in a few tens of seconds) because it has the latest state available in memory: both the latest edit log entries and an up-to-date block mapping. The range of fencing mechanisms includes revoking the namenode’s access to the shared storage directory (typically by using a vendor-specific NFS command), and disabling its network port via a remote management command.
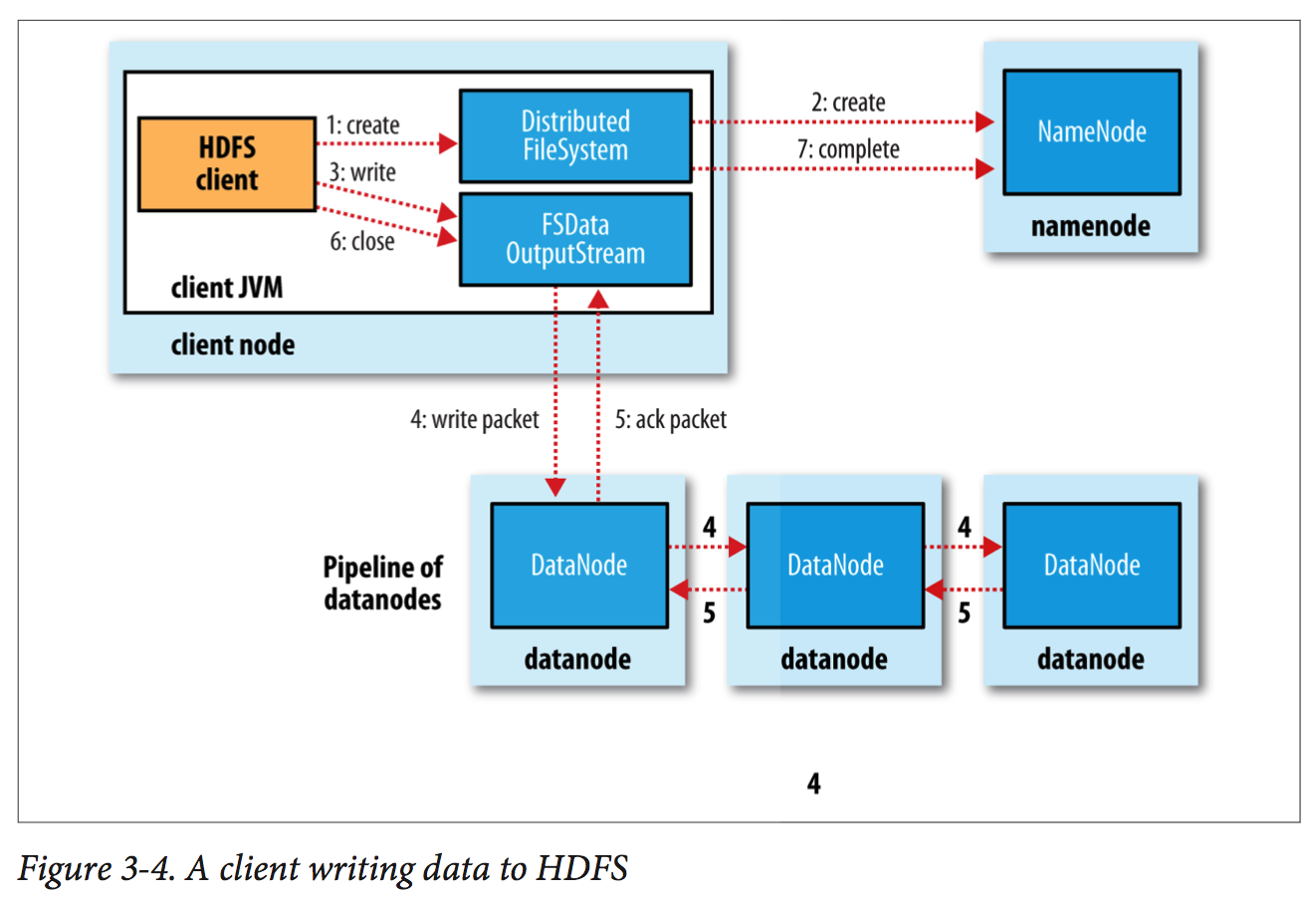
The client creates the file by calling create() on DistributedFileSystem, which makes an RPC call to the namenode to create a new file in the filesystem’s namespace, with no blocks associated with it (step 2). The namenode performs various checks to make sure the file doesn’t already exist and that the client has the right permissions to create the file. If these checks pass, the namenode makes a record of the new file; otherwise, file creation fails and the client is thrown an IOException. The DistributedFileSystem returns an FSDataOutputStream for the client to start writing data to. As the client writes data (step 3), the DFSOutputStream splits it into packets, which it writes to an internal queue called the data queue. The data queue is consumed by the DataStreamer, which is responsible for asking the namenode to allocate new blocks by picking a list of suitable datanodes to store the replicas. The list of datanodes forms a pipeline, and here we’ll assume the replication level is three, so there are three nodes in the pipeline. The DataStreamer streams the packets to the first datanode in the pipeline, which stores each packet and forwards it to the second datanode in the pipeline. Similarly, the second datanode stores the packet and forwards it to the third (and last) datanode in the pipeline (step 4).
YARN
YARN provides APIs for requesting and working with cluster resources, but these APIs are not typically used directly by user code.
Higher Application: Pig, Hive, Impala, Crunch...
Application: MapReduce, Spark, Tez...
Compute: YARN
Storage: HDFS and HBase
YARN provides it core services via two types of long-running daemon: a resource manager (one per cluster) to manage the use of resources across the cluster, and node managers running on all the nodes in the cluster to launch and monitor containers.
To run an application on YARN, a client contacts the resource manager and asks it to run an application master process (step 1 in Figure 4-2). The resource manager then finds a node manager that can launch the application master in a container (steps 2a and 2b).1 Precisely what the application master does once it is running depends on the application. It could simply run a computation in the container it is running in and return the result to the client. Or it could request more containers from the resource managers (step 3), and use them to run a distributed computation (steps 4a and 4b). The latter is what the MapReduce YARN application does.
The YARN scheduler to allocate resources to applications according to some defined policy. Three schedulers are available in YARN: the FIFO (first in, first out), Capacity (small job runs first), and Fair Schedulers (all jobs running on dynamically balanced resources).
Hadoop I/O
-
Date Integrity HDFS transparently checksums all data written to it and by default verifies checksums when reading data. The CRC-32C (32-bit cyclic redundancy check) checksum is created for every 512 bytes of data by default. When a client detects an error when reading a block, it reports it, the namenode marks the block replica as corrupt and schedules a copy from other data node.
-
Compression Hadoop applications process large datasets, so you should strive to take advantage of compression. Try to use a compression format that supports splitting (like bzip2), and consider splitting the file into chunks in the application, and compress each chunk separately using any supported compression format, make sure the compressed chunks are approximately the size of a HDFS block.
-
Serialization Serialization is used in two quite distinct areas of distributed data processing: for interprocess communication (RPC) and for persistent storage. Hadoop comes with a large selection of Writable classes, and some of them are variable-length encoding. Like you can switch from VIntWritable to VLongWritable because their encoding are actually the same; Text is a Writable for UTF-8 sequences; RawComparator permits implementors to compare records read from a stream without deserializing them into objects, thereby avoiding any overhead of object creation.
-
File-Based Data Structure Hadoop’s SequenceFile class provides a persistent data structure for binary key-value pairs. To use it as a logfile format, you would choose a key, such as timestamp represented by a LongWritable, and the value would be a Writable that represents the quantity being logged. A sequence file consists of a header followed by one or more records. A sync marker is written before the start of every block. The format of a block is a field indicating the number of records in the block, followed by four compressed fields: the key lengths, the keys, the value lengths, and the values. A MapFile is a sorted SequenceFile with an index to permit lookups by key. Avro datafiles use a schema to describe the objects stored, so it portable for different programming language.
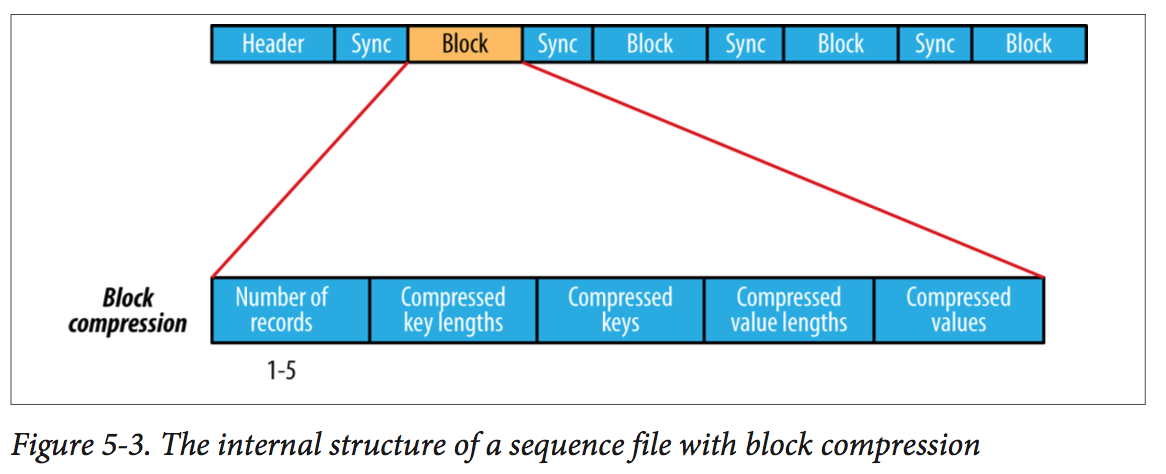
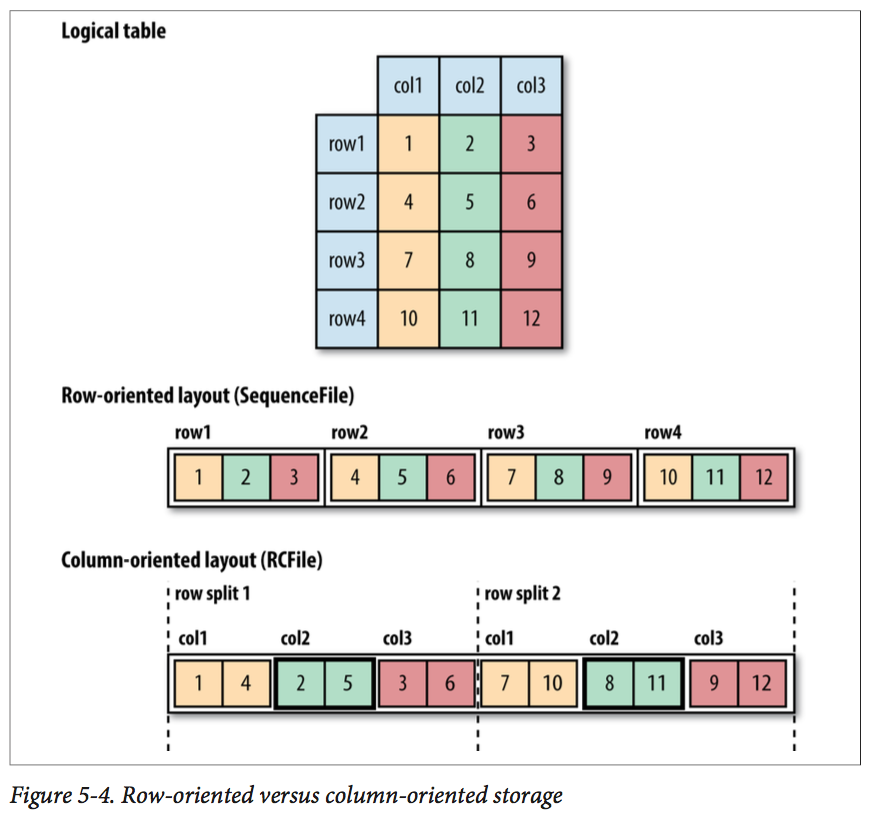
- Column-Oriented Formats
With row-oriented storage, the whole row is loaded into memory even though only the second column is actually read. With column-oriented storage, only the column 2 parts of the file need to be read into memory. In general, column-oriented formats work well when queries access only a small number of columns in the table. Conversely, row-oriented formats are appropriate when a large number of columns of a single row are needed for processing at the same time.
Column-oriented formats need more memory for reading and writing, since they have to buffer a row split in memory, rather than just a single row. So Column-oriented formats are not suited to streaming writes, as the current file cannot be recovered if the writer process fails.
Part II: MapReduce
Develop a MapReduce App
Writing a program in MapReduce following a certain pattern. You start by writing your map and reduce functions, ideally with unit tests to make sure they do what you expect. The you write a driver program to run a job, which can run from your IDE using a small subset of data to check that it is working.
When the program runs as expected against the small dataset, you can unleash it on a cluster. Running against the full dataset is likely to expose some more issues. which you can fix as before, by expanding your tests and altering your mapper or reducer to handle the new cases.
After the program is working, you may wish to do some tuning, first by running through some standard checks for making MapReduce programs faster and then by doing task profiling. Profiling distributed program is not easy, but Hadoop has hooks to aid in the process.
Write a Unit Test with MRUnit:
public class MaxTemperatureMapperTest {
@Test
public void processesValidRecord() throws IOException, InterruptedException {
Text value = new Text("0043011990999991950051518004+68750+023550FM-12+0382" + "99999V0203201N00261220001CN9999999N9-00111+99999999999");
new MapDriver<LongWritable, Text, Text, IntWritable>().withMapper(new MaxTemperatureMapper())
.withInput(new LongWritable(0), value)
.withOutput(new Text("1950"), new IntWritable(-11))
.runTest();
}
@Test
public void returnsMaximumIntegerInValues() throws IOException, InterruptedException {
new ReduceDriver<Text, IntWritable, Text, IntWritable>().withReducer(new MaxTemperatureReducer())
.withInput(new Text("1950"), Arrays.asList(new IntWritable(10), new IntWritable(5)))
.withOutput(new Text("1950"), new IntWritable(10))
.runTest();
}
@Test
public void test() throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "file:///");
conf.set("mapreduce.framework.name", "local");
conf.setInt("mapreduce.task.io.sort.mb", 1);
Path input = new Path("input/ncdc/micro");
Path output = new Path("output");
FileSystem fs = FileSystem.getLocal(conf);
fs.delete(output, true); // delete old output
MaxTemperatureDriver driver = new MaxTemperatureDriver();
driver.setConf(conf);
int exitCode = driver.run(new String[] { input.toString(), output.toString() });
assertThat(exitCode, is(0));
checkOutput(conf, output);
}
}
You can also use the Tool interface, to write a driver to run the MapReduce job in a Local Job Runner
public class MaxTemperatureDriver extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
if (args.length != 2) {
System.err.printf("Usage: %s [generic options] <input> <output>\n", getClass().getSimpleName());
ToolRunner.printGenericCommandUsage(System.err);
return -1;
}
Job job = new Job(getConf(), "Max temperature");
job.setJarByClass(getClass());
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MaxTemperatureMapper.class);
job.setCombinerClass(MaxTemperatureReducer.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new MaxTemperatureDriver(), args);
System.exit(exitCode);
}
}
For more complex problems, it is worth considering a higher-level language than Map‐Reduce, such as Pig, Hive, Cascading, Crunch, or Spark. One immediate benefit is that it frees you from having to do the translation into MapReduce jobs, allowing you to concentrate on the analysis you are performing.
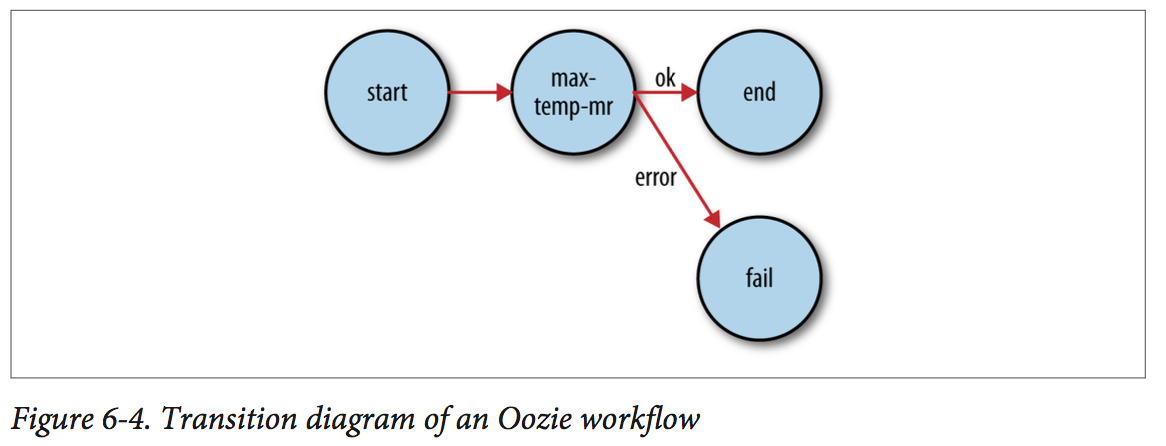
In Oozie parlance, a workflow is a DAG of action nodes and control-flow nodes. Workflow definitions are written in XML using the Hadoop Process Definition Lan‐ guage, the specification for which can be found on the Oozie website.
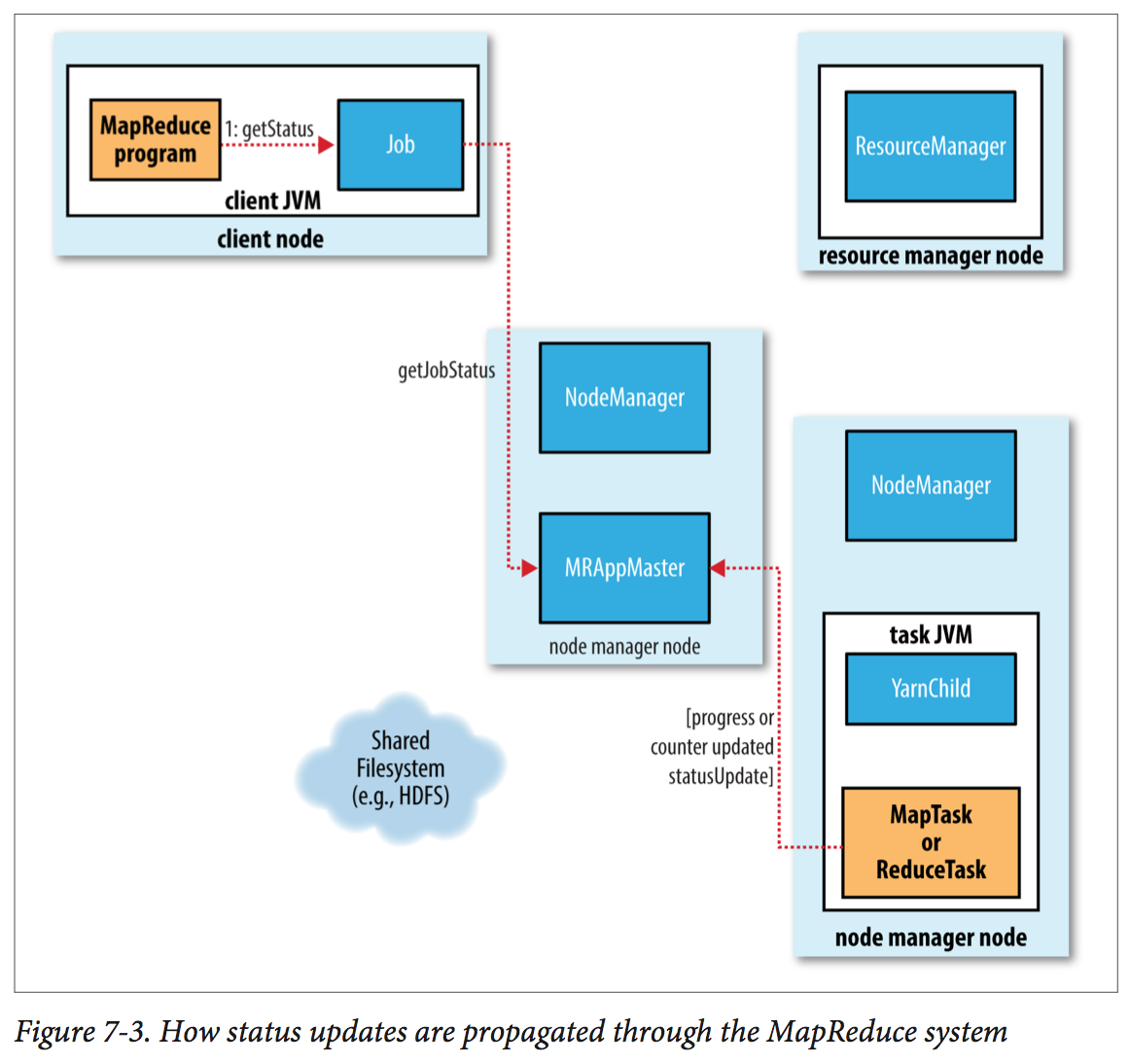
How MapReduce Works
You can run a MapReduce job with a single method call: submit() on a Job object (you can also call waitForCompletion(). This call conceals a great deal of processing behind the scenes:
- The client, which submits the MapReduce job.
- The YARN resource manager, which coordinates the allocation of compute resources on the cluster. (ZooKeeper).
- The YARN node manager, which launch and monitor the compute containers on machines in the cluster.
- The MapReduce application master, which coordinates the tasks running the MapReduce job. The application master and the MapReduce tasks run in containers that are scheduled by the resource manager and managed by the node managers.
- This distributed filesystem (normally HDFS), which is use for sharing job files between the other entities.
Shuffle and Sort
Each map task has a circular memory buffer that it writes the output to. The buffer is 100 MB by default. When the contents of the buffer reach a certain threshold size (80%), a background thread will start to spill the contents to disk. Before it writes to disk, the thread first divides the data into partitions corresponding to the reducers that they will ultimately be sent to. Within each partition, the background thread performs an in-memory sort by key, and if there is a combiner function, it is run on the output of the sort. Running the combiner function makes for a more compact map output, so there is less data to write to local disk and to transfer to the reducer.
As each map tasks complete successfully, they notify their application master using the heartbeat mechanism. A thread in reducer periodically asks the master for map output hosts until it has retrieve them all, also merges the map outputs, maintaining their sort ordering.
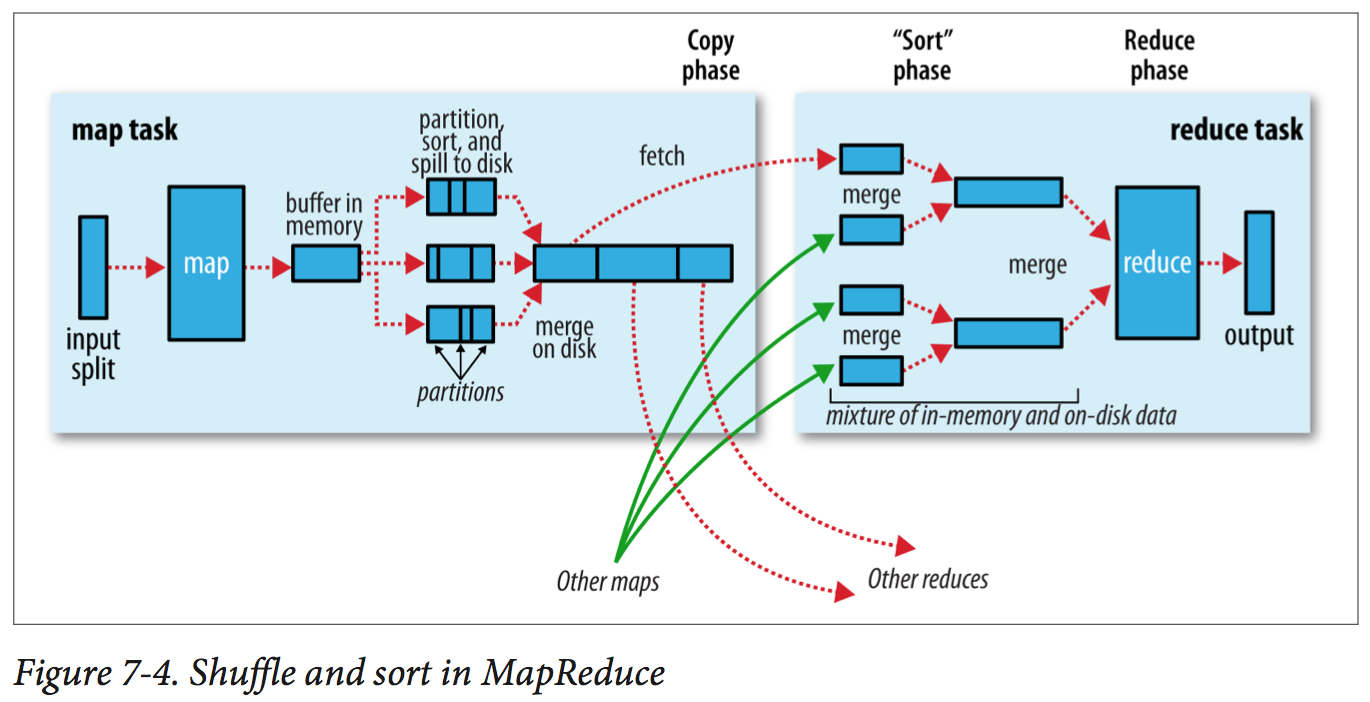
Speculative Execution
When Hadoop detects a task is running slower than expected, it launches another equivalent task as a backup. When either of them completed first, the other one will be killed.
The OutputCommitter protocol ensure that jobs and tasks either succeed or fail cleanly. If applications write side files in their tasks’ working directories, the side files for tasks that successfully complete will be promoted to the output directory automatically, whereas failed tasks will have their side files deleted.
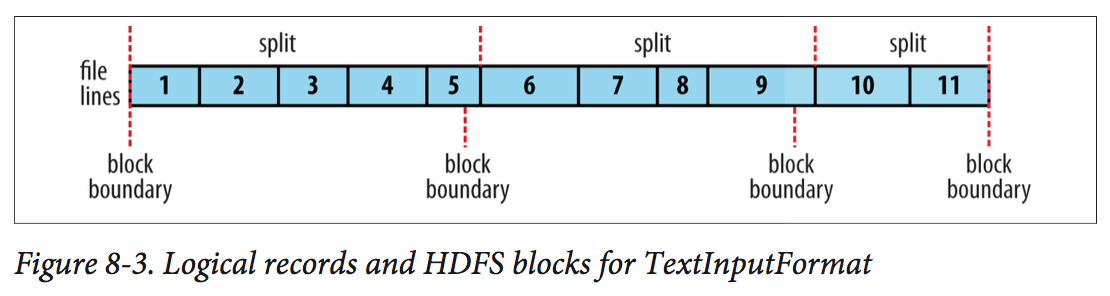
MapReduce Types and Formats
The logical records that FileInputFormats define ususally do not fit neatly into HDFS blocks. As shown below: A single file is broken into lines, and the line boundaries do not correspond with the HDFS block boundaries.
Hadoop maintains some built-in counters for every job, and these report various metrics. MapReduce allows user code to define a set of counters, which are then incremented as desired in the mapper or reducer. Counters are defined by a Java enum, which serves to group related counters.
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
parser.parse(value);
if (parser.isValidTemperature()) {
int airTemperature = parser.getAirTemperature();
context.write(new Text(parser.getYear()), new IntWritable(airTemperature));
} else if (parser.isMalformedTemperature()) {
System.err.println("Ignoring possibly corrupt input: " + value);
context.getCounter(Temperature.MALFORMED).increment(1);
} else if (parser.isMissingTemperature()) {
context.getCounter(Temperature.MISSING).increment(1);
}
// dynamic counter
context.getCounter("TemperatureQuality", parser.getQuality()).increment(1);
}
Part III: Hadoop Operations
Setting Up a Hadoop Cluster
Cloudera Manager and Apache Ambari are examples of dedicated tools for instal‐ ling and managing a Hadoop cluster over its whole lifecycle. They provide a simple web UI, and are the recommended way to set up a Hadoop cluster for most users and operators.
For example, a 200-node cluster with 24 TB of disk space per node, a block size of 128 MB, and a replication factor of 3 has room for about 2 million blocks (or more): 200 × 24,000,000 MB ⁄ (128 MB × 3). So in this case, setting the namenode memory to 12,000 MB would be a good starting point.
Administering Hadoop
Part IV: Related Projects
Avro
Avro, Thrift, Protocol Buffers (Protobuff) all provide efficient, cross-language serialization of data using a schema (schema evolution), and code generation for the java folks.
Apache Avro is a language-neutral data serialization system to address the major downside of Hadoop Writables: lack of language portability. Avro data is described using a language-independent schema. Avro schemas are usually written in JSON, and data is usually encoded using a binary format.
Avro specifies an object container format for sequences of objects, similar to Hadoop’s sequence file. An Avro datafile has a metadata section where the schema is stored, which makes the file self-describing. Avro datafiles support compression and are splittable, which is crucial for a MapReduce data input format.
A simple Avro schema called StringPair.avsc for representing a pair of strings as a record:
{
"type": "record",
"name": "StringPair",
"doc": "A pair of strings.",
"fields": [
{"name": "left", "type": "string"},
{"name": "right", "type": "string"}
]
}
or in an IDL:
record Person {
string userName;
union { null, long } favouriteNumber;
array<string> interests;
}
Schema.Parser parser = new Schema.Parser(); Schema schema = parser.parse(
getClass().getResourceAsStream("StringPair.avsc"));
GenericRecord datum = new GenericData.Record(schema); datum.put("left", "L");
datum.put("right", "R");
// serialize the record to an output stream
ByteArrayOutputStream out = new ByteArrayOutputStream();
DatumWriter<GenericRecord> writer = new GenericDatumWriter<GenericRecord>(schema);
Encoder encoder = EncoderFactory.get().binaryEncoder(out, null); writer.write(datum, encoder);
encoder.flush();
out.close();
// read the object back from the byte buffer
DatumReader<GenericRecord> reader =
new GenericDatumReader<GenericRecord>(schema);
Decoder decoder = DecoderFactory.get().binaryDecoder(out.toByteArray(), null);
GenericRecord result = reader.read(null, decoder); assertThat(result.get("left").toString(), is("L")); assertThat(result.get("right").toString(), is("R"));
Protocol Buffers
- Defining Your Protocol Format (.proto), for Address Book Application.
syntax = "proto2";
package tutorial;
option java_package = "com.example.tutorial";
option java_outer_classname = "AddressBookProtos";
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phones = 4;
}
message AddressBook {
repeated Person people = 1;
}
- Compiling Your Protocol Buffers
protoc -I=$SRC_DIR --java_out=$DST_DIR $SRC_DIR/addressbook.proto
Protocol Buffers and O-O Design: Protocol buffer classes are basically dumb data holders, they do not make good first class citizen in a object model. If you want to add richer behavior to a generated class, the best way to do this is to wrap the generated class, in an application-specific class. You should never add behavior to the generated classes by inheriting from them.
- Parsing and Serialization
Finally, each protocol buffer class has methods for writing and reading messages of your chosen type using the protocol buffer binary format. These include:
byte[] toByteArray();: serializes the message and returns a byte array containing its raw bytes.
static Person parseFrom(byte[] data);: parses a message from the given byte array.
void writeTo(OutputStream output);: serializes the message and writes it to an OutputStream.
static Person parseFrom(InputStream input);: reads and parses a message from an InputStream.
These are just a couple of the options provided for parsing and serialization. Again, see the Message API reference for a complete list.
- Writing A Message
Here is a program which reads an AddressBook from a file, adds one new Person to it based on user input, and writes the new AddressBook back out to the file again. The parts which directly call or reference code generated by the protocol compiler are highlighted.
import com.example.tutorial.AddressBookProtos.AddressBook;
import com.example.tutorial.AddressBookProtos.Person;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.InputStreamReader;
import java.io.IOException;
import java.io.PrintStream;
class AddPerson {
// This function fills in a Person message based on user input.
static Person PromptForAddress(BufferedReader stdin,
PrintStream stdout) throws IOException {
Person.Builder person = Person.newBuilder();
stdout.print("Enter person ID: ");
person.setId(Integer.valueOf(stdin.readLine()));
stdout.print("Enter name: ");
person.setName(stdin.readLine());
stdout.print("Enter email address (blank for none): ");
String email = stdin.readLine();
if (email.length() > 0) {
person.setEmail(email);
}
while (true) {
stdout.print("Enter a phone number (or leave blank to finish): ");
String number = stdin.readLine();
if (number.length() == 0) {
break;
}
Person.PhoneNumber.Builder phoneNumber =
Person.PhoneNumber.newBuilder().setNumber(number);
stdout.print("Is this a mobile, home, or work phone? ");
String type = stdin.readLine();
if (type.equals("mobile")) {
phoneNumber.setType(Person.PhoneType.MOBILE);
} else if (type.equals("home")) {
phoneNumber.setType(Person.PhoneType.HOME);
} else if (type.equals("work")) {
phoneNumber.setType(Person.PhoneType.WORK);
} else {
stdout.println("Unknown phone type. Using default.");
}
person.addPhones(phoneNumber);
}
return person.build();
}
// Main function: Reads the entire address book from a file,
// adds one person based on user input, then writes it back out to the same
// file.
public static void main(String[] args) throws Exception {
if (args.length != 1) {
System.err.println("Usage: AddPerson ADDRESS_BOOK_FILE");
System.exit(-1);
}
AddressBook.Builder addressBook = AddressBook.newBuilder();
// Read the existing address book.
try {
addressBook.mergeFrom(new FileInputStream(args[0]));
} catch (FileNotFoundException e) {
System.out.println(args[0] + ": File not found. Creating a new file.");
}
// Add an address.
addressBook.addPeople(
PromptForAddress(new BufferedReader(new InputStreamReader(System.in)),
System.out));
// Write the new address book back to disk.
FileOutputStream output = new FileOutputStream(args[0]);
addressBook.build().writeTo(output);
output.close();
}
}
- Extending a Protocol Buffer
If you want your new buffers to be backwards-compatible, and your old buffers to be forward-compatible – and you almost certainly do want this – then there are some rules you need to follow. In the new version of the protocol buffer:
you must not change the tag numbers of any existing fields.
you must not add or delete any required fields.
you may delete optional or repeated fields.
you may add new optional or repeated fields but you must use fresh tag numbers (i.e. tag numbers that were never used in this protocol buffer, not even by deleted fields).
Parquet
Apache Parquet is a columnar storage format that can efficiently store nested data.
Columnar formats are attractive since they enable greater efficiency, in terms of both file size and query performance. File sizes are usually smaller than row-oriented equivalents since in a columnar format the values from one column are stored next to each other, which usually allows a very efficient encoding. A column storing a timestamp, for example, can be encoded by storing the first value and the differences between subsequent values (which tend to be small due to temporal locality: records from around the same time are stored next to each other). Query performance is improved too since a query engine can skip over columns that are not needed to answer a query.
Flume
Flume is designed for high-volume ingestion into Hadoop of event-based data. The canonical example is using Flume to collect logfiles from a bank of web servers, then moving the log events from those files into new aggregated files in HDFS for processing.
To use Flume, we need to run a Flume agent, which is a long-lived Java process that runs sources and sinks, connected by channels. A source in Flume produces events and de‐ livers them to the channel, which stores the events until they are forwarded to the sink. You can think of the source-channel-sink combination as a basic Flume building block.
Flume vs. Kafka
• Flume is an ingest solution - an easy and reliable way to store data streaming data in HDFS while solving common issues such as reliability, optimal file sizes, file formats, updating metadata and partitioning. • Kafka, like all message brokers, is a solution to service decoupling and message queueing. It’s a possible data source for Hadoop, but requires additional components in order to integrate with HDFS.
Sqoop
Apache Sqoop is an open source tool that allows users to extract data from a structured data store into Hadoop for further processing. This processing can be done with MapReduce programs or other higher-level tools such as Hive. (It’s even possible to use Sqoop to move data from a database into HBase.)
Sqoop’s import tool will run a MapReduce job that connects to the MySQL database and reads the table. By default, this will use four map tasks in parallel to speed up the import process. Each task will write its imported results to a different file, but all in a common directory.
Pig
A Pig Latin program is made up of a series of operations, or transformations, that are applied to the input data to produce output. Taken as a whole, the operations describe a data flow, which the Pig execution environment translates into an executable representation and then runs. Under the covers, Pig turns the transformations into a series of MapReduce jobs, but as a programmer you are mostly unaware of this, which allows you to focus on the data rather than the nature of the execution.
Pig has two execution types or modes: local mode and MapReduce mode. Execution modes for Apache Tez and Spark. Grunt has line-editing facilities like those found in GNU Readline.
-- max_temp.pig: Finds the maximum temperature by year
records = LOAD 'input/ncdc/micro-tab/sample.txt'
AS (year:chararray, temperature:int, quality:int);
filtered_records = FILTER records BY temperature != 9999 AND quality IN (0, 1, 4, 5, 9);
grouped_records = GROUP filtered_records BY year; max_temp = FOREACH grouped_records GENERATE group,
MAX(filtered_records.temperature); DUMP max_temp;
Hive
Hive was created to make it possible for analysts with strong SQL skills (but meager Java programming skills) to run queries on the huge volumes of data that Facebook stored in HDFS.
In normal use, Hive runs on your workstation and converts your SQL query into a series of jobs for execution on a Hadoop cluster. Hive organizes data into tables, which provide a means for attaching structure to data stored in HDFS. Metadata—such as table schemas is stored in a database called the metastore. By default, the metastore service runs in the same JVM as the Hive service and contains an embedded Derby database instance backed by the local disk. This is called the embedded metastore configuration.
Both Tez and Spark are general directed acyclic graph (DAG) engines that offer more flexibility and higher performance than MapReduce. For example, unlike MapReduce, where intermediate job output is materialized to HDFS, Tez and Spark can avoid replication overhead by writing the intermediate output to local disk, or even store it in memory (at the request of the Hive planner).
hive> SET hive.execution.engine=tez;
CREATE TABLE logs (ts BIGINT, line STRING) PARTITIONED BY (dt STRING, country STRING);
CREATE TABLE bucketed_users (id INT, name STRING) CLUSTERED BY (id) INTO 4 BUCKETS;
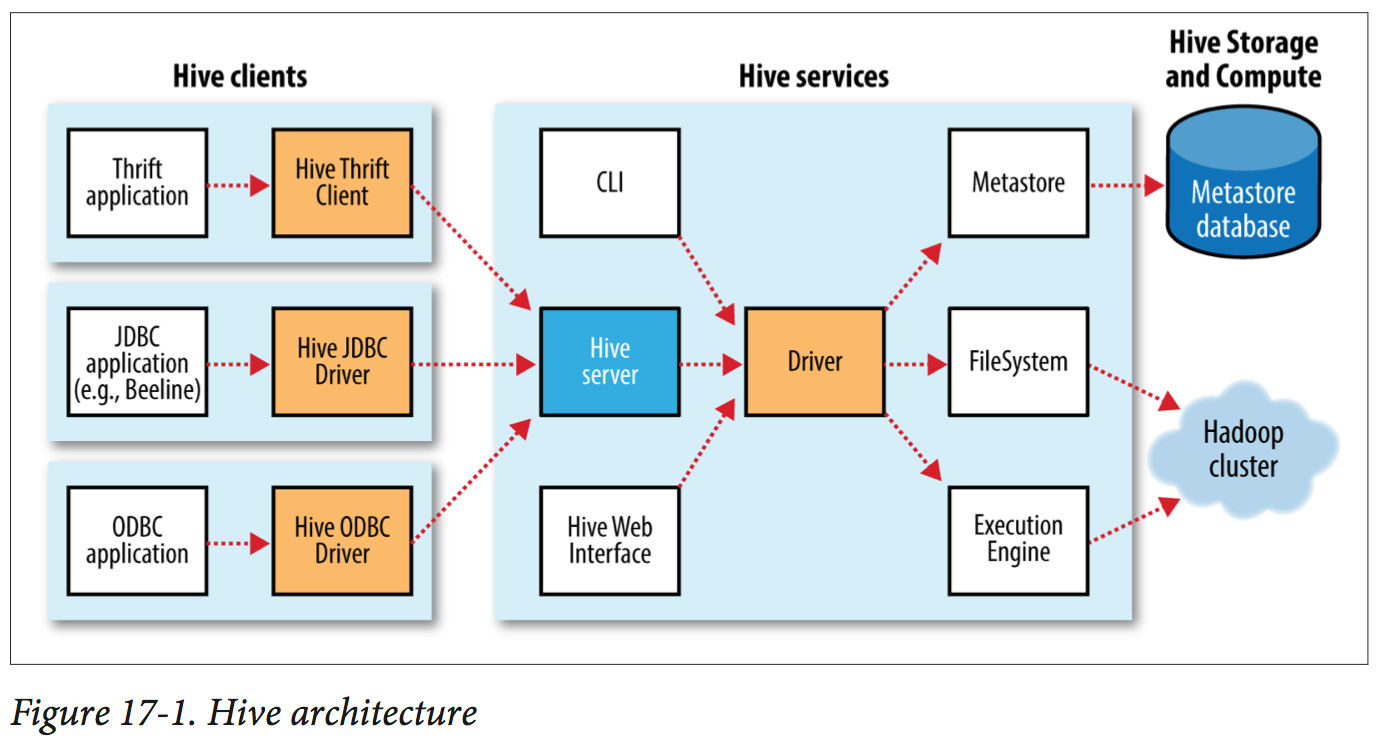
HDFS does not provide in-place file updates, so changes resulting from inserts, updates, and deletes are stored in small delta files. Delta files are periodically merged into the base table files by MapReduce jobs that are run in the background by the metastore.
Cloudera Impala, an open source interactive SQL engine, was one of the first, giving an order of magnitude performance boost compared to Hive running on MapReduce. Also Spark SQL and Phoenix on HBase.
Crunch
Apache Crunch is a higher-level API for writing MapReduce pipelines.
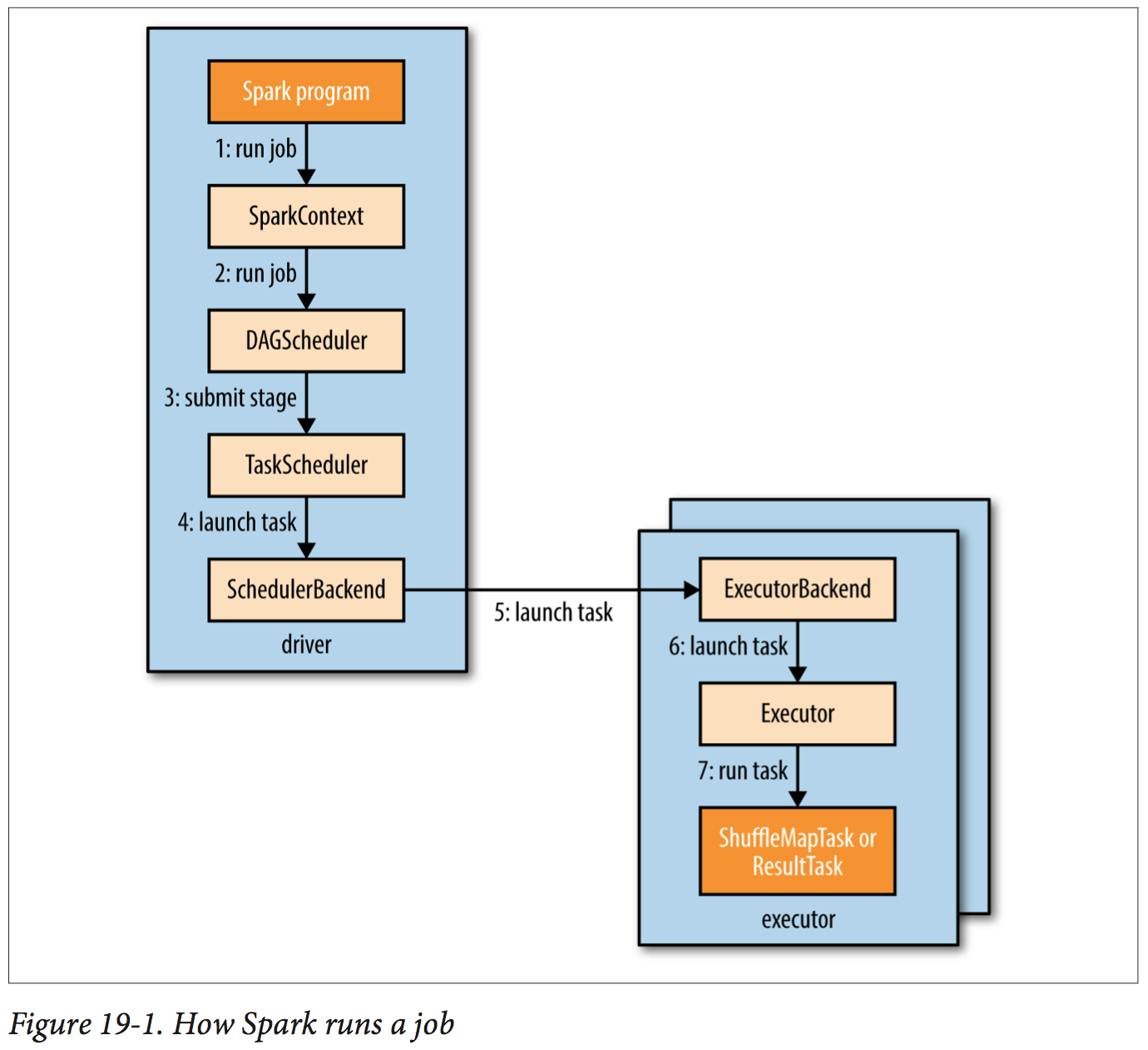
Spark
Apache Spark is a cluster computing framework for large-scale data processing. Unlike most of the other processing frameworks discussed in this book, Spark does not use MapReduce as an execution engine; instead, it uses its own distributed runtime for executing work on a cluster. Apache Spark achieves high performance for both batch and streaming data, using a state-of-the-art DAG scheduler, a query optimizer, and a physical execution engine. Unlike MapReduce, Spark’s DAG engine can process arbitrary pipelines of operators and translate them into a single job for the user.
Spark is proving to be a good platform on which to build analytics tools, too, and to this end the Apache Spark project includes modules for machine learning (MLlib), graph processing (GraphX), stream processing (Spark Streaming), and SQL (Spark SQL).
Like MapReduce, Spark has the concept of a job. A Spark job is more general than a MapReduce job, though. since it is made up of an arbitrary directed acyclic graph (DAG) of stages, each of which is roughly equivalent to a map or reduce phase in MapReduce. Stages are split into tasks by the Spark runtime and are run in parallel on partitions of an RDD (Resilient Distributed Dataset) spread across the cluster—just like tasks in MapReduce. A job always runs in the context of an application that serves to group RDDs and shared variables.
RDD are the heart of every Spark program, Data sharing is slow in MapReduce due to replication, serialization, and disk I/O. Most of the Hadoop applications, they spend more than 90% of the time doing HDFS read-write operation. RDD is a read-only, partitioned collection of records, it supports in-memory processing computation. This means, it stores the state of memory as an object across the jobs and the object is sharable between those jobs. Data sharing in memory is 10 to 100 times faster than network and Disk.
Scala application to find the maximum temperature, using Spark
import org.apache.spark.SparkContext._
import org.apache.spark.{SparkConf, SparkContext}
object MaxTemperature {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Max Temperature") val sc = new SparkContext(conf)
sc.textFile(args(0))
.map(_.split("\t"))
.filter(rec => (rec(1) != "9999" && rec(2).matches("[01459]"))) .map(rec => (rec(0).toInt, rec(1).toInt))
.reduceByKey((a, b) => Math.max(a, b)).saveAsTextFile(args(1))
} }
HBase
The first component to provide online access was HBase, a key-value store that uses HDFS for its underlying storage. HBase provides both online read/write access of individual rows and batch operations for reading and writing data in bulk, making it a good solution for building applications on.
In synopsis, HBase tables are like those in an RDBMS, only cells are versioned, rows are sorted, and columns can be added on the fly by the client as long as the column family they belong to preexists.
HBase Versus RDBMS
HBase is a distributed, column-oriented data storage system. It picks up where Hadoop left off by providing random reads and writes on top of HDFS. It has been designed from the ground up with a focus on scale in every direction: tall in numbers of rows (billions), wide in numbers of columns (millions), and able to be horizontally partitioned and replicated across thousands of commodity nodes automatically. The table schemas mirror the physical storage, creating a system for efficient data structure serialization, storage, and retrieval. The burden is on the application developer to make use of this storage and retrieval in the right way.
Typical RDBMSs are fixed-schema, row-oriented databases with ACID properties and a sophisticated SQL query engine. The emphasis is on strong consistency, referential integrity, abstraction from the physical layer, and complex queries through the SQL language. You can easily create secondary indexes; perform complex inner and outer joins; and count, sum, sort, group, and page your data across a number of tables, rows, and columns.
Building an Online Query Application
The existing weather dataset described in previous chapters contains observations for tens of thousands of stations over 100 years. We will build a simple online (as opposed to batch) interface that allows a user to navigate the different stations and page through their historical temperature observations in time order.
Schema Design (for each station will be ordered with most recent observation first): - stations table: stationId (row key), info:name, info:location, info:description - observations table: stationId + reverse-order timestamp (row key), data:airtemp
public class RowKeyConverter {
private static final int STATION_ID_LENGTH = 12;
/**
* @return A row key whose format is: <station_id> <reverse_order_timestamp>
*/
public static byte[] makeObservationRowKey(String stationId, long observationTime) {
byte[] row = new byte[STATION_ID_LENGTH + Bytes.SIZEOF_LONG]; Bytes.putBytes(row, 0, Bytes.toBytes(stationId), 0, STATION_ID_LENGTH); long reverseOrderTimestamp = Long.MAX_VALUE - observationTime; Bytes.putLong(row, STATION_ID_LENGTH, reverseOrderTimestamp);
return row;
} }
static final byte[] INFO_COLUMNFAMILY = Bytes.toBytes("info");
static final byte[] NAME_QUALIFIER = Bytes.toBytes("name");
static final byte[] LOCATION_QUALIFIER = Bytes.toBytes("location");
static final byte[] DESCRIPTION_QUALIFIER = Bytes.toBytes("description");
public Map<String, String> getStationInfo(HTable table, String stationId) throws IOException {
Get get = new Get(Bytes.toBytes(stationId)); get.addFamily(INFO_COLUMNFAMILY);
Result res = table.get(get);
if (res == null) {
return null;
}
Map<String, String> resultMap = new LinkedHashMap<String, String>();
resultMap.put("name", getValue(res, INFO_COLUMNFAMILY, NAME_QUALIFIER));
resultMap.put("location", getValue(res, INFO_COLUMNFAMILY, LOCATION_QUALIFIER));
resultMap.put("description", getValue(res, INFO_COLUMNFAMILY, DESCRIPTION_QUALIFIER));
return resultMap;
}
private static String getValue(Result res, byte[] cf, byte[] qualifier) {
byte[] value = res.getValue(cf, qualifier);
return value == null? "": Bytes.toString(value);
}
ZooKeeper
ZooKeeper gives you a set of tools to build distributed applications that can safely handle partial failures. It provides an open source, shared repository of implementations and recipes of common coordination patterns.
One way of understanding ZooKeeper is to think of it as providing a high-availability filesystem. It doesn’t have files and directories, but a unified concept of a node, called a znode, that acts both as a container of data (like a file) and a container of other znodes (like a directory). Znodes form a hierarchical namespace, and a natural way to build a membership list is to create a parent znode with the name of the group and child znodes with the names of the group members (servers).
ZooKeeper uses a protocol called Zab that runs in two phases, which may be repeated indefinitely:
Phase 1: Leader election The machines in an ensemble go through a process of electing a distinguished member, called the leader. The other machines are termed followers. This phase is finished once a majority (or quorum) of followers have synchronized their state with the leader.
Phase 2: Atomic broadcast All write requests are forwarded to the leader, which broadcasts the update to the followers. When a majority have persisted the change, the leader commits the up‐ date, and the client gets a response saying the update succeeded. The protocol for achieving consensus is designed to be atomic, so a change either succeeds or fails. It resembles a two-phase commit.
Every update made to the znode tree is given a globally unique identifier, updates are ordered, so if zxid z1 is less than z2, then z1 happened before z2, according to ZooKeeper, which can keep sequential consistency.
Sessions are kept alive by the client sending ping requests (also known as heartbeats) whenever the session is idle for longer than a certain period.
public class ConnectionWatcher implements Watcher {
private static final int SESSION_TIMEOUT = 5000;
protected ZooKeeper zk;
private CountDownLatch connectedSignal = new CountDownLatch(1);
public void connect(String hosts) throws IOException, InterruptedException {
zk = new ZooKeeper(hosts, SESSION_TIMEOUT, this); // register itself
connectedSignal.await();
}
@Override
public void process(WatchedEvent event) {
if (event.getState() == KeeperState.SyncConnected) {
connectedSignal.countDown();
}
}
public void close() throws InterruptedException {
zk.close();
}
}
Part V: Case Studies
Composable Data at Center
With dozens of data sources and formats, and even standardized data models subject to interpretation, we were facing an enormous semantic integration problem. Our biggest challenge was not the size of the data (we knew Hadoop could scale to our needs) but the sheer complexity of cleaning, managing, and transforming it for our needs. We needed higher-level tools to manage that complexity.
Note that a variety of data types are all nested in a common person record rather than in separate datasets. This supports the most common usage pattern for this data: looking at a complete record—without requiring downstream operations to do a number of expensive joins between datasets.
A series of Crunch pipelines are used to manipulate the data into a PCollection
// Avro IDL for common data types
@namespace("com.cerner.example")
protocol PersonProtocol {
record Demographics {
string firstName;
string lastName;
string dob;
... }
record LabResult {
string personId;
string labDate;
int labId;
int labTypeId;
int value; }
record Medication {
string personId;
string medicationId;
string dose;
string doseUnits;
string frequency;
... }
record Diagnosis {
string personId;
string diagnosisId;
string date;
... }
record Allergy {
string personId;
int allergyId;
int substanceId;
...
}
//Represents a person's record from a single source.
record PersonRecord {
string personId;
Demographics demographics;
array<LabResult> labResults;
array<Allergy> allergies;
array<Medication> medications;
array<Diagnosis> diagnoses; .. .
}
}
Cascading
Cascading substitutes the keys and values used in MapReduce with simple field names and a data tuple model, where a tuple is simply a list of values. For the second issue, Cascading departs from map and reduce operations directly by introducing higher-level abstractions as alternatives: Functions, Filters, Aggregators, and Buffers.