Sorting
Let’s go through a number of sorting algorithms first:
- Bubble Sort | Runtime: O(n^2) average and worst case. Space: O(1).
- Selection Sort | Runtime: O(n^2) average and worst case. Space: O(1).
- Insertion Sort | Runtime: between O(n) and O(n^2). Space: O(1).
- More efficient than above simple sort.
- To begin, the leftmost number is considered fully sorted. Take the next number and compare to the already sorted number to its left, If the already sorted number is larger, the two numbers swap.
- Heap Sort | Runtime: O(nlog(n)) average. Space: O(1)
- First turning the array into a max heap in O(n) operations.
- Then repeatedly swaps the first value of the list with the last value. decreasing the range of values considered in the heap operation by one, and shifting the new first value into its position in the heap.
- Priority queue is implemented on the efficient binary heap
- Merge Sort | Runtime: O(nlog(n)) average and worst case. Space: Depends.
- Merge sort divides the array in half, sorts each of those halves, and then merges them back together.
- The space complexity of merge sort is O(n) due to the auxiliary space used to merge parts of the array.
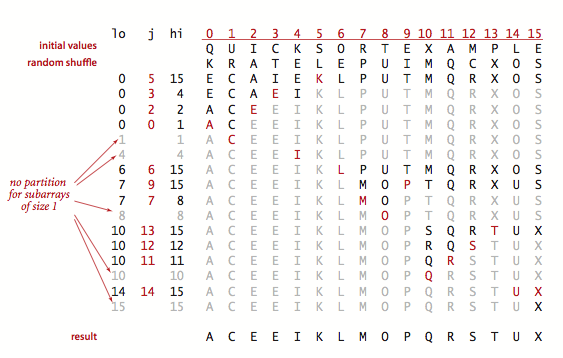
- Quick Sort | Runtime: O(nlog(n)) average, O(n^2) worst case. Space: O(log(n)).
- Pick a random element and partition the array, such that all numbers that are less than the partitioning element come before all elements that are greater than it.
- Radix Sort | Runtime: O(kn); Bucket Sort | Runtime: O(k + n).
- They are both non-comparative sorting algorithm that sorts data by grouping them by each digit (e.g., base-10 arithmetic) or bucket.
- E.g. Given a very large array of Person objects, sort the people in increasing order of age. The Age are in small range, we can make 1 year each as a bucket and get O(n) running time.
A well-implemented quicksort is usually the best choice for sorting. Which is a top-bot
An in-place sort is one which uses O(1) space; a stable sort is one where entries which are equal appear in specific circumstances.
Sorting problems come in two flavors: 1. use sorting to make subsequent steps in an algorithm simpler; 2. design a custom sorting routine. For the former, it’s fine to use a library sort function, possibly with a custom comparator. For the later, use a data structure like a BST, heap or array indexed by values.
In Java, to sort an array, use Arrays.sort(array), to sort a list use Collections.sort(list). Collections.sort(list) internally proceeds by forming an array, calling Arrays.sort(array), and then writing the result back into the list. so the space complexity is always O(n).
Compare Algorithms
| algorithm | stable? | inplace? | running time | extra space | sweet spot |
|---|---|---|---|---|---|
| insertion sort for strings | yes | yes | between \(n\) and \(n^2\) | 1 | small arrays, arrays in order |
| quicksort | no | yes | \(n\log_2 n\) | \(\log n\) | general-purpose, when space is tight |
| mergesort | yes | no | \(n\log_2 n\) | \(n\) | general-purpose, stable sort |
| 3-way quicksort | no | yes | between \(n\) and \(n\log_2 n\) | \(\log n\) | large numbers of equal keys |
| LSD string sort | yes | no | \(w_{max}n\) | \(n\) | short fixed-length strings |
| MSD string sort | yes | no | between \(n\) and \(wn\) | \(n + w_{max}R\) | random strings |
| 3-way string quicksort | no | yes | between \(n\) and \(wn\log R\) | \(w_{max} + \log n\) | general-purpose, strings with long prefix matches |
Quick Sort Sample
public class QuickSort {
public static void swap(int[] array, int i, int j) {
int tmp = array[i];
array[i] = array[j];
array[j] = tmp;
}
public static int partition(int[] array, int left, int right) {
// Pick a pivot point. Can be an element
int pivot = array[(left + right) / 2];
while (left <= right) { // Until we've gone through the whole array
// Find element on left that should be on right
while (array[left] < pivot) {
left++;
}
// Find element on right that should be on left
while (array[right] > pivot) {
right--;
}
// Swap elements, and move left and right indices
if (left <= right) {
swap(array, left, right);
left++;
right--;
}
}
return left;
}
public static void quickSort(int[] array, int left, int right) {
int index = partition(array, left, right);
if (left < index - 1) { // Sort left half
quickSort(array, left, index - 1);
}
if (index < right) { // Sort right half
quickSort(array, index, right);
}
}
public static void main(String[] args) {
int[] array = new int[] { 1, 4, 5, 2, 8, 9 };
quickSort(array, 0, array.length - 1);
System.out.print(Arrays.toString(array));
}
}
Merge Sort Sample

// top-down mergesort
public static void mergeSort(int[] array) {
int[] helper = new int[array.length];
mergeSort(array, helper, 0, array.length - 1);
}
public static void mergeSort(int[] array, int[] helper, int low, int high) {
if (low < high) {
int middle = (low + high) / 2;
mergeSort(array, helper, low, middle); // Sort left half
mergeSort(array, helper, middle + 1, high); // Sort right half
merge(array, helper, low, middle, high); // Merge them
}
}
public static void merge(int[] array, int[] helper, int low, int middle, int high) {
/* Copy both halves into a helper array */
for (int i = low; i <= high; i++) {
helper[i] = array[i];
}
int helperLeft = low;
int helperRight = middle + 1;
int current = low;
/* Iterate through helper array. Compare the left and right
* half, copying back the smaller element from the two halves
* into the original array. */
while (helperLeft <= middle && helperRight <= high) {
if (helper[helperLeft] <= helper[helperRight]) {
array[current] = helper[helperLeft];
helperLeft++;
} else { // If right element is smaller than left element
array[current] = helper[helperRight];
helperRight++;
}
current++;
}
/* Copy the rest of the left side of the array into the
* target array; no need to copy the rest of the right side. */
int remaining = middle - helperLeft;
for (int i = 0; i <= remaining; i++) {
array[current + i] = helper[helperLeft + i];
}
}
Radix Sort sample
All the data items are divided into 10 groups, each group use a linked list to hold all value for this group.
421 240 035 532 305 430 124 // unsorted array
(240 430) (421) (532) (124) (035 305) // sorted on 1s digit
(305) (421 124) (430 532 035) (240) // sorted on 10s digit
(035) (124) (240) (305) (421 430) (532) // sorted on 100s digit
public class RadixSort {
static void countSort(int[] nums, int exp) {
int len = nums.length;
int[] output = new int[len];
int[] count = new int[10];
// Store count of occurrences in count[]
for (int i = 0; i < len; i++)
count[(nums[i] / exp) % 10]++;
// Change count[i] so that count[i] now contains actual position of this digit in output[]
for (int i = 1; i < 10; i++)
count[i] += count[i - 1];
// Build the output array
for (int i = len - 1; i >= 0; i--) {
output[count[(nums[i] / exp) % 10] - 1] = nums[i];
count[(nums[i] / exp) % 10]--;
}
// Copy the output array to nums, so that nums now contains sorted numbers according to current
// digit
for (int i = 0; i < len; i++)
nums[i] = output[i];
}
static void radixSort(int[] nums) {
int max = 0;
for (int num : nums) {
max = Math.max(max, num);
}
// Do counting sort for every digit.
for (int exp = 1; max / exp > 0; exp *= 10)
countSort(nums, exp);
}
public static void main(String[] args) {
int nums[] = { 170, 45, 75, 90, 802, 24, 2, 66 };
radixSort(nums);
for (int i = 0; i < nums.length; i++)
System.out.print(nums[i] + " ");
}
}
Bucket Sort Sample
Also called Sort Characters By Frequency Given a string, sort it in decreasing order based on the frequency of characters.
Example: input “tree”, output “eert”; input “Aabb”, output “bbAa”.
public static String frequencySort(String s) {
int[] counts = new int[256];
for (char c : s.toCharArray())
counts[c]++;
@SuppressWarnings("unchecked")
List<Character>[] buckets = new List[s.length() + 1];
for (int i = 0; i < counts.length; i++) {
int frequency = counts[i];
if (buckets[frequency] == null)
buckets[frequency] = new ArrayList<>();
buckets[frequency].add((char) i);
}
StringBuilder sb = new StringBuilder();
for (int pos = buckets.length - 1; pos >= 0; pos--) {
if (buckets[pos] != null) {
for (char c : buckets[pos]) {
for (int i = 0; i < pos; i++)
sb.append(c);
}
}
}
return sb.toString();
}
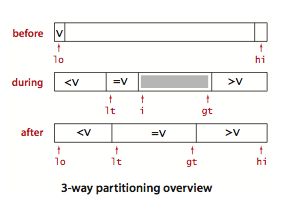
Dutch Flag Partition
Write a program that takes an array A and an index i into A, and rearrange the elements such that all elements less than A[i] (the “pivot”) appear first, followed by elements equal to the pivot, followed by elements greater than the pivot.
We can maintain four subarrays: bottom, middle, unclassified and top.
public enum Color {
RED, WHITE, BLUE
};
public void dutchFlagPartion(int pivotIndex, List<Color> colors) {
Color pivot = colors.get(pivotIndex);
/**
* Keep the following invariants during partitions: <br>
* bottom group: colors.subList(0, smaller). <br>
* middle group: colors.subList(smaller, equal). <br>
* unclassified group: A.suList(equal, larger). <br>
* top group: A.subList(larger, colors.size()).
*/
int smaller = 0, equal = 0, larger = colors.size() - 1;
while (equal <= larger) {
if (colors.get(equal).ordinal() < pivot.ordinal()) {
Collections.swap(colors, smaller++, equal++); // increase both
} else if (colors.get(equal).ordinal() == pivot.ordinal()) {
equal++;
} else {
Collections.swap(colors, equal, larger--);
}
}
}
String Sorting
Key-Indexed Counting
Key-indexed counting uses 11n + 4R + 1 array accesses to stably sort n items whose keys are integers between 0 and R - 1.

// Initialize the arrays, n + R + 1 array accesses
int n = a.length;
String[] aux = new String[n];
int[] count = new int[R + 1];
// Compute frequency counts, 3n array accesses
for (int i = 0; i < n; i++) {
count[a[i].key() + 1]++; // next item's start index!
}
// Transform counts to indices, 3R array accesses
for (int r = 0; r < R; r++) {
count[r + 1] += count[r];
}
// Distribute the items, 5n array accesses
for (int i = 0; i < n; i++) {
aux[count[a[i].key()]++] = a[i];
}
// Copy back, 2n array accesses
for (int i = 0; i < n; i++) {
a[i] = aux[i];
}
LSD String Sorting
Least-Significant-Digit-first (LSD) string sort stably sorts fixed-length strings.
/**
* Rearranges the array of W-character strings in ascending order.
*/
public static void sort(String[] a, int w) {
int n = a.length;
int R = 256; // extend ASCII alphabet size
String[] aux = new String[n];
// sort by key-indexed counting on dth character
for (int d = w - 1; d >= 0; d--) {
// compute frequency counts
int[] count = new int[R + 1];
for (int i = 0; i < n; i++)
count[a[i].charAt(d) + 1]++;
// compute cumulates, transform counts to indices
for (int r = 0; r < R; r++)
count[r + 1] += count[r];
// move data
for (int i = 0; i < n; i++)
aux[count[a[i].charAt(d)]++] = a[i];
// copy back
for (int i = 0; i < n; i++)
a[i] = aux[i];
}
}
/**
* Rearranges the array of 32-bit integers in ascending order. This is about 2-3x faster than
* Arrays.sort().
*/
public static void sort(int[] a) {
final int BITS_PER_BYTE = 8;
final int BITS = 32; // each int is 32 bits
final int R = 1 << BITS_PER_BYTE; // each bytes is between 0 and 255
final int MASK = R - 1; // 0xFF
final int w = BITS / BITS_PER_BYTE; // each int is 4 bytes
int n = a.length;
int[] aux = new int[n];
for (int d = 0; d < w; d++) {
// compute frequency counts
int[] count = new int[R + 1];
for (int i = 0; i < n; i++) {
int c = (a[i] >> BITS_PER_BYTE * d) & MASK;
count[c + 1]++;
}
// compute cumulates
for (int r = 0; r < R; r++)
count[r + 1] += count[r];
// for most significant byte, 0x80-0xFF comes before 0x00-0x7F due to negative sign
if (d == w - 1) {
int shift1 = count[R] - count[R / 2];
int shift2 = count[R / 2];
for (int r = 0; r < R / 2; r++)
count[r] += shift1;
for (int r = R / 2; r < R; r++)
count[r] -= shift2;
}
// move data
for (int i = 0; i < n; i++) {
int c = (a[i] >> BITS_PER_BYTE * d) & MASK;
aux[count[c]++] = a[i];
}
// copy back
for (int i = 0; i < n; i++)
a[i] = aux[i];
}
}
MSD String Sorting
Most-Significant-Digit first (MSD) string sort to handle random strings. It uses key-indexed counting to sort the strings according to their first character, then (recursively) sort the subarrays corresponding to each character. But the till-end small subarrays all need to initialize count[] arrays, likely to dominate the rest of the sort. So the switch to insertion sort for small subarray is a must for MSD string sort.
To sort n random strings from an R-character alphabet, MSD string sort examines about \(n\log_R n\) characters.
MSD string sort is cache-inefficient, too much memory storing count[], too much overhead reinitializing count[] and aux[].
public class MSD {
private static final int R = 256; // extended ASCII alphabet size
private static final int CUTOFF = 15; // cutoff to insertion sort
/**
* Rearranges the array of extended ASCII strings in ascending order.
*/
public static void sort(String[] a) {
int n = a.length;
String[] aux = new String[n];
sort(a, 0, n - 1, 0, aux);
}
// return dth character of s, -1 if d = length of string, plus 1 to be 0, the first entry of count
private static int charAt(String s, int d) {
assert d >= 0 && d <= s.length();
if (d == s.length())
return -1;
return s.charAt(d);
}
// sort from a[lo] to a[hi], starting at the dth character
private static void sort(String[] a, int lo, int hi, int d, String[] aux) {
// cutoff to insertion sort for small subarrays
if (hi <= lo + CUTOFF) {
insertion(a, lo, hi, d);
return;
}
// compute frequency counts
int[] count = new int[R + 2];
for (int i = lo; i <= hi; i++) {
int c = charAt(a[i], d);
count[c + 2]++;
}
// transform counts to indicies
for (int r = 0; r < R + 1; r++)
count[r + 1] += count[r];
// distribute
for (int i = lo; i <= hi; i++) {
int c = charAt(a[i], d);
aux[count[c + 1]++] = a[i];
}
// copy back
for (int i = lo; i <= hi; i++)
a[i] = aux[i - lo];
// recursively sort for each character (excludes sentinel -1)
for (int r = 0; r < R; r++) {
sort(a, lo + count[r], lo + count[r + 1] - 1, d + 1, aux);
}
}
// insertion sort a[lo..hi], starting at dth character
private static void insertion(String[] a, int lo, int hi, int d) {
for (int i = lo; i <= hi; i++)
for (int j = i; j > lo && less(a[j], a[j - 1], d); j--)
exch(a, j, j - 1);
}
// exchange a[i] and a[j]
private static void exch(String[] a, int i, int j) {
String temp = a[i];
a[i] = a[j];
a[j] = temp;
}
// is v less than w, starting at character d
private static boolean less(String v, String w, int d) {
// assert v.substring(0, d).equals(w.substring(0, d));
for (int i = d; i < Math.min(v.length(), w.length()); i++) {
if (v.charAt(i) < w.charAt(i))
return true;
if (v.charAt(i) > w.charAt(i))
return false;
}
return v.length() < w.length();
}
private static final int BITS_PER_BYTE = 8;
private static final int BITS_PER_INT = 32; // each Java int is 32 bits
/**
* Rearranges the array of 32-bit integers in ascending order. Currently assumes that the integers are nonnegative.
*/
public static void sort(int[] a) {
int n = a.length;
int[] aux = new int[n];
sort(a, 0, n - 1, 0, aux);
}
// MSD sort from a[lo] to a[hi], starting at the dth byte
private static void sort(int[] a, int lo, int hi, int d, int[] aux) {
// cutoff to insertion sort for small subarrays
if (hi <= lo + CUTOFF) {
insertion(a, lo, hi, d);
return;
}
// compute frequency counts (need R = 256)
int[] count = new int[R + 1];
int mask = R - 1; // 0xFF;
int shift = BITS_PER_INT - BITS_PER_BYTE * d - BITS_PER_BYTE;
for (int i = lo; i <= hi; i++) {
int c = (a[i] >> shift) & mask;
count[c + 1]++;
}
// transform counts to indicies
for (int r = 0; r < R; r++)
count[r + 1] += count[r];
// distribute
for (int i = lo; i <= hi; i++) {
int c = (a[i] >> shift) & mask;
aux[count[c]++] = a[i];
}
// copy back
for (int i = lo; i <= hi; i++)
a[i] = aux[i - lo];
// no more bits
if (d == 4)
return;
// recursively sort for each character
if (count[0] > 0)
sort(a, lo, lo + count[0] - 1, d + 1, aux);
for (int r = 0; r < R; r++)
if (count[r + 1] > count[r])
sort(a, lo + count[r], lo + count[r + 1] - 1, d + 1, aux);
}
// TODO: insertion sort a[lo..hi], starting at dth character
private static void insertion(int[] a, int lo, int hi, int d) {
for (int i = lo; i <= hi; i++)
for (int j = i; j > lo && a[j] < a[j - 1]; j--)
exch(a, j, j - 1);
}
// exchange a[i] and a[j]
private static void exch(int[] a, int i, int j) {
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}
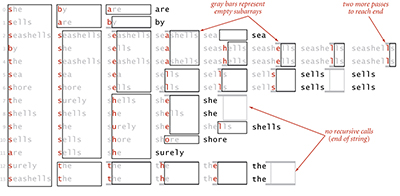
3-Way String Quicksort
3-way string (radix) quicksort is faster than standard quick sort because it avoids re-comparing long common prefixes. Comparing to MSD string sort, it is cache-friendly, in place and has a shorter inner loop.
public class Quick3String {
private static final int CUTOFF = 15; // cutoff to insertion sort
// do not instantiate
private Quick3String() {
}
/**
* Rearranges the array of strings in ascending order.
*/
public static void sort(String[] a) {
sort(a, 0, a.length - 1, 0);
assert isSorted(a);
}
// return the dth character of s, -1 if d = length of s
private static int charAt(String s, int d) {
assert d >= 0 && d <= s.length();
if (d == s.length())
return -1;
return s.charAt(d);
}
// 3-way string quicksort a[lo..hi] starting at dth character
private static void sort(String[] a, int lo, int hi, int d) {
// cutoff to insertion sort for small subarrays
if (hi <= lo + CUTOFF) {
insertion(a, lo, hi, d);
return;
}
int lt = lo, gt = hi;
int v = charAt(a[lo], d);
int i = lo + 1;
while (i <= gt) {
int t = charAt(a[i], d);
if (t < v)
exch(a, lt++, i++);
else if (t > v)
exch(a, i, gt--);
else
i++;
}
// a[lo..lt-1] < v = a[lt..gt] < a[gt+1..hi].
sort(a, lo, lt - 1, d);
if (v >= 0)
sort(a, lt, gt, d + 1);
sort(a, gt + 1, hi, d);
}
// sort from a[lo] to a[hi], starting at the dth character
private static void insertion(String[] a, int lo, int hi, int d) {
for (int i = lo; i <= hi; i++)
for (int j = i; j > lo && less(a[j], a[j - 1], d); j--)
exch(a, j, j - 1);
}
// exchange a[i] and a[j]
private static void exch(String[] a, int i, int j) {
String temp = a[i];
a[i] = a[j];
a[j] = temp;
}
private static boolean less(String v, String w, int d) {
assert v.substring(0, d).equals(w.substring(0, d));
for (int i = d; i < Math.min(v.length(), w.length()); i++) {
if (v.charAt(i) < w.charAt(i))
return true;
if (v.charAt(i) > w.charAt(i))
return false;
}
return v.length() < w.length();
}
// is the array sorted
private static boolean isSorted(String[] a) {
for (int i = 1; i < a.length; i++)
if (a[i].compareTo(a[i - 1]) < 0)
return false;
return true;
}
}
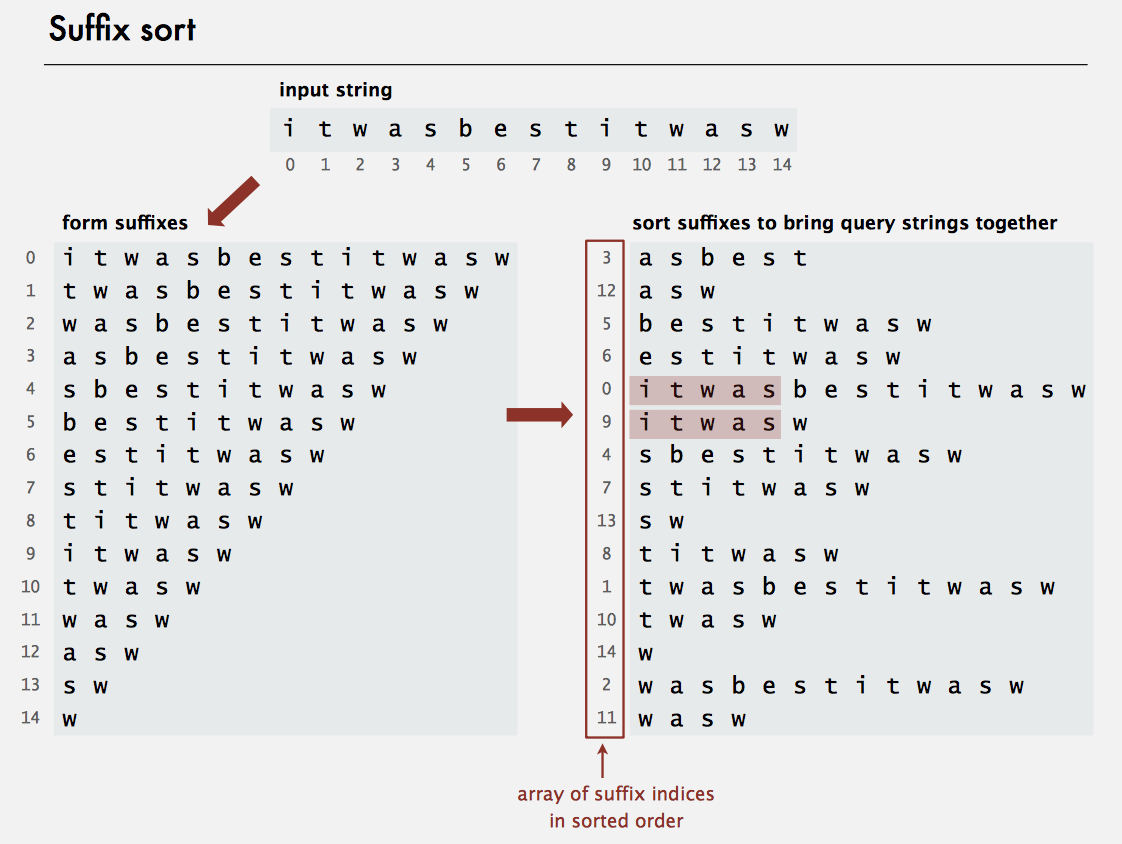
Keyword-in-context Search
Using 3-way string quicksort, we can build a suffix array from a random string of length n with space proportional to n and \(~2n\ln n\) character compares, on the average. The worst case is when all the characters are equal, the sort examines every character in each suffix and thus takes more than quadratic time, \(N^2\log N\)
With the improved suffix arrays, we can solve the suffix sorting and longest repeated substring problems in the linear time.
Question: Compute the longest common substring that appears in two given strings.
Solution: The 1st solution is to compute the suffix array of each string and apply a merging operation to determine the longest common substring; The 2nd solution is to compute the suffix array of a single string (the concatenation of the two string with the character \1 in the middle).
Solution 1:
public class LongestCommonSubstring {
// Compute the suffix array of each string and apply a merging operation to determine the lcs
public static String lcs(String s, String t) {
SuffixArray suffix1 = new SuffixArray(s);
SuffixArray suffix2 = new SuffixArray(t);
String lcs = "";
int i = 0, j = 0;
while (i < s.length() && j < t.length()) {
int p = suffix1.index(i);
int q = suffix2.index(j);
String x = lcp(s, p, t, q);
if (x.length() > lcs.length())
lcs = x;
if (compare(s, p, t, q) < 0)
i++;
else
j++;
}
return lcs;
}
static class SuffixArray {
private Suffix[] suffixes;
public SuffixArray(String text) {
int n = text.length();
this.suffixes = new Suffix[n];
for (int i = 0; i < n; i++) {
suffixes[i] = new Suffix(text, i);
}
Arrays.sort(suffixes);
}
private class Suffix implements Comparable<Suffix> {
private final String text;
private final int index;
private Suffix(String text, int index) {
this.text = text;
this.index = index;
}
private int length() {
return text.length() - index;
}
private char charAt(int i) {
return text.charAt(index + i);
}
public int compareTo(Suffix that) {
if (this == that)
return 0;
int n = Math.min(this.length(), that.length());
for (int i = 0; i < n; i++) {
if (this.charAt(i) < that.charAt(i))
return -1;
if (this.charAt(i) > that.charAt(i))
return +1;
}
return this.length() - that.length();
}
public String toString() {
return text.substring(index);
}
}
public int index(int i) {
if (i < 0 || i >= suffixes.length)
throw new IllegalArgumentException();
return suffixes[i].index;
}
}
// return the longest common prefix of suffix s[p..] and suffix t[q..]
public static String lcp(String s, int p, String t, int q) {
int n = Math.min(s.length() - p, t.length() - q);
for (int i = 0; i < n; i++) {
if (s.charAt(p + i) != t.charAt(q + i))
return s.substring(p, p + i);
}
return s.substring(p, p + n);
}
private static int compare(String s, int p, String t, int q) {
int n = Math.min(s.length() - p, t.length() - q);
for (int i = 0; i < n; i++) {
if (s.charAt(p + i) != t.charAt(q + i))
return s.charAt(p + i) - t.charAt(q + i);
}
if (s.length() - p < t.length() - q)
return -1;
else if (s.length() - p > t.length() - q)
return +1;
else
return 0;
}
public static void main(String[] args) {
String s = "it was the best of times";
String t = "no, it was the worst of times";
System.out.println("'" + lcs(s, t) + "'");
System.out.println("'" + lcs2(s, t) + "'");
}
}
Solution 2:
// Compute suffix array (3-way string quicksort) of a concatenated string
public static String lcs2(String s, String t) {
int n1 = s.length();
String text = s + '\1' + t;
int n = text.length();
SuffixArrayX suffix = new SuffixArrayX(text);
String lcs = "";
for (int i = 1; i < n; i++) {
// adjacent suffixes both from first text string
if (suffix.index(i) < n1 && suffix.index(i - 1) < n1)
continue;
// adjacent suffixes both from second text string
if (suffix.index(i) > n1 && suffix.index(i - 1) > n1)
continue;
// check if adjacent suffixes longer common substring
int length = suffix.lcp(i);
if (length > lcs.length()) {
lcs = text.substring(suffix.index(i), suffix.index(i) + length);
}
}
return lcs;
}
public class SuffixArrayX {
private static final int CUTOFF = 5; // cutoff to insertion sort
private final char[] text;
private final int[] index; // index[i] = j means text.substring(j) is the ith largest suffix
private final int n; // number of characters in text;
public SuffixArrayX(String text) {
n = text.length();
text = text + '\0';
this.text = text.toCharArray();
this.index = new int[n];
for (int i = 0; i < n; i++) {
index[i] = i;
}
sort(0, n - 1, 0);
}
// 3-way string quicksort lo..hi starting at dth character
private void sort(int lo, int hi, int d) {
if (lo + CUTOFF >= hi) {
insertion(lo, hi, d);
return;
}
int lt = lo, gt = hi;
char v = text[index[lo] + d];
int i = lo + 1;
while (i <= gt) {
char t = text[index[i] + d];
if (t < v)
exch(lt++, i++);
else if (t > v)
exch(i, gt--);
else
i++;
}
sort(lo, lt - 1, d);
if (v > 0)
sort(lt, gt, d + 1);
sort(gt + 1, hi, d);
}
// sort from a[lo] to a[hi], starting at the dth character
private void insertion(int lo, int hi, int d) {
for (int i = lo; i <= hi; i++) {
for (int j = i; j > lo && less(index[j], index[j - 1], d); j--) {
exch(j, j - 1);
}
}
}
// is text[i+d..n) < text[j+d..n)?
private boolean less(int i, int j, int d) {
if (i == j)
return false;
i = i + d;
j = j + d;
while (i < n && j < n) {
if (text[i] < text[j])
return true;
else if (text[i] > text[j])
return false;
i++;
j++;
}
return i > j;
}
private void exch(int i, int j) {
int swap = index[i];
index[i] = index[j];
index[j] = swap;
}
public int index(int i) {
if (i < 0 || i >= n)
throw new IllegalArgumentException();
return index[i];
}
public int lcp(int i) {
if (i < 1 || i >= n)
throw new IllegalArgumentException();
return lcp(index[i], index[i - 1]);
}
// longest common prefix of text[i..n) and text[j..n)
private int lcp(int i, int j) {
int length = 0;
while (i < n && j < n) {
if (text[i] != text[j])
return length;
i++;
j++;
length++;
}
return length;
}
// Returns the ith smallest suffix as a string
public String select(int i) {
if (i < 0 || i >= n)
throw new IllegalArgumentException();
return new String(text, index[i], n - index[i]);
}
// Binary search to get rank of currenty query
public int rank(String query) {
int lo = 0, hi = n - 1;
while (lo <= hi) {
int mid = lo + (hi - lo) / 2;
int cmp = compare(query, index[mid]);
if (cmp < 0)
hi = mid - 1;
else if (cmp > 0)
lo = mid + 1;
else
return mid;
}
return lo;
}
private int compare(String query, int i) {
int m = query.length();
int j = 0;
while (i < n && j < m) {
if (query.charAt(j) != text[i])
return query.charAt(j) - text[i];
i++;
j++;
}
if (i < n)
return -1;
if (j < m)
return +1;
return 0;
}
}
Longest Common Subarray
Also called “Maximum Length of Repeated Subarray”
Given two integer arrays A and B, return the maximum length of an subarray that appears in both arrays.
Example 1:
Input:
A: [1,2,3,2,1]
B: [3,2,1,4,7]
Output: 3
Explanation:
The repeated subarray with maximum length is [3, 2, 1].
Solution 1: Dynamic Programming O(M*N)
// 2D array - Bottom Up
public int findLength(int[] A, int[] B) {
int ans = 0;
int m = A.length, n = B.length;
int[][] dp = new int[m + 1][n + 1];
for (int i = m - 1; i >= 0; --i) {
for (int j = n - 1; j >= 0; --j) {
if (A[i] == B[j]) {
dp[i][j] = dp[i + 1][j + 1] + 1;
if (ans < dp[i][j])
ans = dp[i][j];
}
}
}
return ans;
}
// 2D array - Top Down
public int findLength(int[] A, int[] B) {
int ans = 0;
int m = A.length, n = B.length;
int[][] dp = new int[m + 1][n + 1];
dp[0][0] = 0;
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (A[i - 1] == B[j - 1]) {
dp[i][j] = dp[i - 1][j - 1] + 1;
if (ans < dp[i][j])
ans = dp[i][j];
}
}
}
return ans;
}
// 1D array
public int findLength(int[] A, int[] B) {
int ans = 0;
int m = A.length, n = B.length;
int[] dp = new int[n + 1];
for (int i = 0; i < m; i++) {
for (int j = n - 1; j >= 0; j--) {
if (A[i] == B[j]) {
dp[j + 1] = dp[j] + 1;
if (ans < dp[j + 1])
ans = dp[j + 1];
} else {
dp[j + 1] = 0;
}
}
}
return ans;
}
Solution 2: Binary Search with Rolling Hash O((M+N)*log(min(M,N)))
int P = 113;
int MOD = 1_000_000_007;
int Pinv = BigInteger.valueOf(P).modInverse(BigInteger.valueOf(MOD)).intValue();
private int[] rolling(int[] source, int length) {
int[] ans = new int[source.length - length + 1];
long h = 0, power = 1;
if (length == 0)
return ans;
for (int i = 0; i < source.length; ++i) {
h = (h + source[i] * power) % MOD;
if (i < length - 1) {
power = (power * P) % MOD;
} else {
ans[i - (length - 1)] = (int) h;
h = (h - source[i - (length - 1)]) * Pinv % MOD;
if (h < 0)
h += MOD;
}
}
return ans;
}
private boolean check(int guess, int[] A, int[] B) {
Map<Integer, List<Integer>> hashes = new HashMap<>();
int k = 0;
for (int x : rolling(A, guess)) {
hashes.computeIfAbsent(x, z -> new ArrayList<>()).add(k++);
}
int j = 0;
for (int x : rolling(B, guess)) {
for (int i : hashes.getOrDefault(x, new ArrayList<Integer>()))
if (Arrays.equals(Arrays.copyOfRange(A, i, i + guess), Arrays.copyOfRange(B, j, j + guess))) {
return true;
}
j++;
}
return false;
}
public int findLength(int[] A, int[] B) {
int lo = 0, hi = Math.min(A.length, B.length) + 1;
while (lo < hi) {
int mi = (lo + hi) / 2;
if (check(mi, A, B))
lo = mi + 1;
else
hi = mi;
}
return lo - 1;
}
Sorting Boot Camp
Intersection of Two Arrays
Given two arrays, write a function to compute their intersection.
Example:
Given nums1 = [1, 2, 2, 1], nums2 = [2, 2], return [2].
Note:
Each element in the result must be unique.
The result can be in any order.
Are we going to sort the arrays? If not, we can use two hash sets, the average time complexity O(n); To sort the shorter array, then we can use binary search; To sort both arrays, then we can use two pointers. They are both O(n(log(n)))
public static int[] intersection(int[] nums1, int[] nums2) {
List<Integer> list = new ArrayList<>();
Arrays.sort(nums1);
Arrays.sort(nums2);
int i = 0, j = 0;
while (i < nums1.length && j < nums2.length) {
if (nums1[i] == nums2[j] && (i == 0 || nums1[i] != nums1[i - 1])) {
list.add(nums1[i]);
i++;
j++;
} else if (nums1[i] < nums2[j]) {
i++;
} else {
j++;
}
}
int[] result = new int[list.size()];
for (int k = 0; k < result.length; k++)
result[k] = list.get(k);
return result;
}
Remove First-Name Duplicates
Design an efficient algorithm for removing all first-name duplicates from an array. For example if the input is [(Ian, Botham), (David, Gower), (Ian, Bell), (Ian, Chappell)], one result could be [(Ian, Bell), (David, Gower)].
We can avoid the additional space complexity if we can reuse the input array for storing the final result. First we sort the array, which brings equal elements together. Sorting can be done in O(nlog(n)) time. The subsequent elimination of duplicates takes O(n) time.
int writeIdx = 0;
for (int i = 1; i < A.size(); i++) {
if (!A.get(i).firstName.equals(A.get(writeIdx).firstName)) {
A.set(++writeIdx, A.get(i));
}
}
// Shrink array size.
A.subList(++writeIdx, A.size()).clear;
Smallest Nonconstructible Value
Write a program which takes an array of positive integers and returns the smallest number which is not the sum of a subset of elements of the array.
Generalizing, suppose a collection of numbers can produce every value up to and including V. Now consider the effect of adding a new element u to the collection. If u <= V + 1, we can still produce every value up to and including V + u, but not able to produce V + u + 1. On the other hand, if u > V + 1, then even by adding u to the collection we cannot produce V + 1.
public static int smallestNonconstructibleValue(int[] A) {
Arrays.sort(A);
int maxConstructibleValue = 0;
for (int a : A) {
if (a > maxConstructibleValue + 1)
break;
maxConstructibleValue += a;
}
return maxConstructibleValue + 1;
}
Find Minimum Waiting Time
Given service times for a set of queries, compute a schedule for processing the queries that minimizes the total waiting time. The time a query waits before its turn comes is called its waiting time. For example, if the service times are <2, 5, 1, 3>, the minimum waiting time is 10 = (0 + (1) + (1 + 2) + (1 + 2 + 3)) against the sorted service times <1, 2, 3, 5>.
For example, the query #3 needs to wait for both #1 and #2 done first; and #2 needs to week for #1 done first. You can image a cumulated waiting time going on here!
public int minimumTotalWaitingTime(List<Integer> serviceTimes) {
// Sort the service times in increasing order
Collections.sort(serviceTimes);
int totalWaitingTime = 0;
for (int i = 0; i < serviceTimes.size(); i++) {
int numRemainingQueries = serviceTimes.size() - i - 1;
totalWaitingTime += serviceTimes.get(i) * numRemainingQueries;
}
return totalWaitingTime;
}
Find Minimum Visit Times
A visit takes place at a fixed time, and he can only check on tasks taking place at exactly that time. For example if there are tasks at times[0, 3], [2, 6], [3, 4], [6, 9], then visit times 0, 2, 3, 6 cover all tasks. A smaller set of visit times that also cover all tasks is 3, 6.
You are given a set of closed intervals, how to find a minimum sized set of numbers that cover all the intervals.
The idea is: sort all the intervals, comparing on right endpoints, select the first interval’s right endpoint. Iterate through the intervals, looking for the first one not covered by this right endpoint (compare with left side). As soon as such an interval is found, select its right endpoint and continue the iteration.
Calendar’s Concurrent Events
Write a program that takes a set of events, and determines the maximum number of events that take place concurrently.
- How to calculate overlap of 2 intervals?
The overlap exists if max(a0, b0) < min(a1, b1) for all following 3 cases:
case 1: b ends before a ends:
a: a0 |-------------| a1
b: b0 |-----| b1
case 2: b ends after a ends:
a: a0 |--------| a1
b: b0 |--------| b1
case 3: b starts after a ends: (negative overlap)
a: a0 |----| a1
b: b0 |----| b1
- How to prevent double booking?
class MyCalendar {
List<int[]> books = new ArrayList<>();
// O(n)
public boolean book(int start, int end) {
for (int[] b : books)
if (Math.max(b[0], start) < Math.min(b[1], end))
return false;
books.add(new int[] { start, end });
return true;
}
}
class MyCalendar2 {
private TreeMap<Integer, Integer> treeMap = new TreeMap<>();
// O(log(n))
public boolean book(int start, int end) {
// find the closest start time at left side of end
Integer i = treeMap.lowerKey(end);
if (i != null && i >= start)
return false;
// find the closest start time at left side of start
i = treeMap.lowerKey(start);
if (i != null && treeMap.get(i) > start)
return false;
treeMap.put(start, end);
return true;
}
}
- How to prevent triple booking?
We can reuse above MyCalendar to track the overlaps with any previous books.
class MyCalendarII {
private List<int[]> books = new ArrayList<>();
public boolean book(int s, int e) {
MyCalendar overlaps = new MyCalendar();
for (int[] b : books) {
if (Math.max(b[0], s) < Math.min(b[1], e)) // overlap exist
if (!overlaps.book(Math.max(b[0], s), Math.min(b[1], e)))
return false; // overlaps overlapped
}
books.add(new int[] { s, e });
return true;
}
}
- How to count concurrent events?
We can log the start and end of each event on the timeline. Then we scan the timeline to figure out the maximum number of ongoing event at any time.
class MyCalendarIII {
private Map<Integer, Integer> times = new TreeMap<>();
public int book(int s, int e) {
times.put(s, times.getOrDefault(s, 0) + 1); // 1 new event will be starting at times[s]
times.put(e, times.getOrDefault(e, 0) - 1); // 1 new event will be ending at times[e];
int ongoing = 0, k = 0;
for (int v : times.values())
k = Math.max(k, ongoing += v);
return k;
}
}
Merge Overlapped Intervals
public List<Interval> merge(List<Interval> intervals) {
List<Interval> list = new ArrayList<>(); // or linked list
Collections.sort(intervals, (a, b) -> (a.start - b.start));
for (Interval interval : intervals) {
if (list.isEmpty()) {
list.add(interval);
continue;
}
Interval last = list.get(list.size() - 1);
if (last.end < interval.start)
list.add(interval);
else {
last.end = Math.max(last.end, interval.end);
}
}
return list;
}
Insert an Interval and Merge
Given a set of non-overlapping intervals, insert a new interval into the intervals (merge if necessary).
You may assume that the intervals were initially sorted according to their start times.
Example 1:
Given intervals [1,3],[6,9], insert and merge [2,5] in as [1,5],[6,9].
Example 2:
Given [1,2],[3,5],[6,7],[8,10],[12,16], insert and merge [4,9] in as [1,2],[3,10],[12,16].
This is because the new interval [4,9] overlaps with [3,5],[6,7],[8,10].
3 steps to merge or insert an interval.
public List<Interval> insert(List<Interval> intervals, Interval newInterval) {
List<Interval> results = new ArrayList<>();
int i = 0;
while (i < intervals.size() && intervals.get(i).end < newInterval.start) {
results.add(intervals.get(i++));
}
while (i < intervals.size() && intervals.get(i).start <= newInterval.end) {
int start = Math.min(intervals.get(i).start, newInterval.start);
int end = Math.max(intervals.get(i).end, newInterval.end);
newInterval = new Interval(start, end);
i++;
}
results.add(newInterval);
while (i < intervals.size()) {
results.add(intervals.get(i));
i++;
}
return results;
}
Merge Overlapping Intervals
Given a collection of intervals, merge all overlapping intervals.
For example,
Given [1,3],[2,6],[8,10],[15,18],
return [1,6],[8,10],[15,18].
The idea is to sort the intervals by their starting points. Then, we take the first interval and compare its end with the next intervals starts. As long as they overlap, we update the end to be the max end of the overlapping intervals. Once we find a non overlapping interval, we can add the previous “extended” interval and start over.
Sorting takes O(nlog(n)) and merging the intervals takes O(n). So, the resulting algorithm takes O(nlog(n)).
public List<Interval> mergeOverlappingIntervals(List<Interval> intervals) {
if (intervals.size() <= 1)
return intervals;
Collections.sort(intervals, (a, b) -> (a.start - b.start));
List<Interval> result = new LinkedList<Interval>();
int start = intervals.get(0).start;
int end = intervals.get(0).end;
for (Interval interval : intervals) {
if (interval.start <= end) {
end = Math.max(end, interval.end);
} else {
result.add(new Interval(start, end));
start = interval.start;
end = interval.end;
}
}
// add the last one
result.add(new Interval(start, end));
return result;
}
Stream as Disjoint Intervals
Given a data stream input of non-negative integers a1, a2, …, an, …, summarize the numbers seen so far as a list of disjoint intervals.
For example, suppose the integers from the data stream are 1, 3, 7, 2, 6, …, then the summary will be:
[1, 1] [1, 1], [3, 3] [1, 1], [3, 3], [7, 7] [1, 3], [7, 7] [1, 3], [6, 7]
Use TreeMap to easily find the lower and higher keys, the key is the start of the interval. Merge the lower and higher intervals when necessary.
private TreeMap<Integer, Interval> treeMap = new TreeMap<>();
public List<Interval> addNumberAndReturnDisjointIntervals(int val) {
if (treeMap.containsKey(val))
return new ArrayList<>(treeMap.values());
Integer l = treeMap.lowerKey(val);
Integer h = treeMap.higherKey(val);
if (l != null && h != null && treeMap.get(l).end + 1 == val && h == val + 1) {
treeMap.get(l).end = treeMap.get(h).end;
treeMap.remove(h);
} else if (l != null && treeMap.get(l).end + 1 >= val) {
treeMap.get(l).end = Math.max(treeMap.get(l).end, val);
} else if (h != null && h == val + 1) {
treeMap.put(val, new Interval(val, treeMap.get(h).end));
treeMap.remove(h);
} else {
treeMap.put(val, new Interval(val, val));
}
return new ArrayList<>(treeMap.values());
}
Partition and Sort Array
You are given an array of student objects. Each student has an integer-valued age field that is to be treated as a key. Rearrange the elements of the array so that students of equal age appear together.
You might think we can just use a TreeSet to sort it. Here we are discussing to rearrange the elements in place. In the program below we use two hash tables to track the subarrays. One is the starting offset of the subarray. the other is its size. As soon as the subarray becomes empty. we remove it.
To appear sorted by age, we can use a BST-based map to map ages to counts. The time complexity becomes O(n + mlog(m)).
public static void groupByAge(List<Person> people) {
Map<Integer, Integer> ageToCount = new TreeMap<>();
for (Person p : people) {
if (ageToCount.containsKey(p.age)) {
ageToCount.put(p.age, ageToCount.get(p.age) + 1);
} else {
ageToCount.put(p.age, 1);
}
}
Map<Integer, Integer> ageToOffset = new HashMap<>();
int offset = 0;
for (Map.Entry<Integer, Integer> kc : ageToCount.entrySet()) {
ageToOffset.put(kc.getKey(), offset);
offset += kc.getValue();
}
while (!ageToOffset.isEmpty()) {
Map.Entry<Integer, Integer> from = ageToOffset.entrySet().iterator().next();
Integer toAge = people.get(from.getValue()).age;
Integer toValue = ageToOffset.get(toAge);
Collections.swap(people, from.getValue(), toValue);
// Use ageToCount to see when we are finished with a particular age.
Integer count = ageToCount.get(toAge) - 1;
ageToCount.put(toAge, count);
if (count > 0) {
ageToOffset.put(toAge, toValue + 1);
} else {
ageToOffset.remove(toAge);
}
}
}
private static class Person {
public Integer age;
public String name;
public Person(Integer k, String n) {
age = k;
name = n;
}
}
Min Meeting Rooms Required
Given an array of meeting time intervals consisting of start and end times [[s1,e1],[s2,e2],…] (si < ei), find the minimum number of conference rooms required.
For example,
Given [[0, 30],[5, 10],[15, 20]],
return 2.
/* solution1: based on sorting */
public int minMeetingRooms(Interval[] intervals) {
if (intervals == null || intervals.length == 0)
return 0;
int[] starts = new int[intervals.length];
int[] ends = new int[intervals.length];
for (int i = 0; i < intervals.length; i++) {
starts[i] = intervals[i].start;
ends[i] = intervals[i].end;
}
Arrays.sort(starts);
Arrays.sort(ends);
int rooms = 0;
int endsIdx = 0;
for (int i = 0; i < starts.length; i++) {
if (starts[i] < ends[endsIdx])
rooms++;
else
endsIdx++;
}
return rooms;
}
/* solution2: using heap, to track the earliest end time. */
public int minMeetingRooms2(Interval[] intervals) {
if (intervals == null || intervals.length == 0)
return 0;
Arrays.sort(intervals, (a, b) -> (a.start - b.start));
Queue<Interval> heap = new PriorityQueue<Interval>(intervals.length, (a, b) -> (a.end - b.end));
heap.offer(intervals[0]);
for (int i = 1; i < intervals.length; i++) {
// get the meeting room that finishes earliest
Interval interval = heap.poll();
if (intervals[i].start >= interval.end) {
interval.end = intervals[i].end;
} else {
// otherwise, this meeting needs a new room
heap.offer(intervals[i]);
}
// don't forget to put the meeting room back;
heap.offer(interval);
}
return heap.size();
}
Merge Sort a Linked List
Sort a linked list in O(nlog(n)) time using constant space complexity.
We can implement merge sort on a linked list, which has stable result. The time complexity is O(nlog(n)), and space complexity is O(log(n)). To use O(1) space, we can also use increasing block size to iterate through the merge sort.
public ListNode sortList(ListNode head) {
if (head == null || head.next == null)
return head;
// step 1. cut the list to two halves
ListNode prev = null, slow = head, fast = head;
while (fast != null && fast.next != null) {
prev = slow;
slow = slow.next;
fast = fast.next.next;
}
prev.next = null; // disconnect the list
// step 2. sort each half
ListNode l1 = sortList(head);
ListNode l2 = sortList(slow);
// step 3. merge l1 and l2
return merge(l1, l2);
}
private ListNode merge(ListNode l1, ListNode l2) {
if (l1 == null)
return l2;
if (l2 == null)
return l1;
if (l1.val < l2.val) {
l1.next = merge(l1.next, l2);
return l1;
} else {
l2.next = merge(l1, l2.next);
return l2;
}
}
Merge K sorted lists
You are given an array of k linked-lists lists, each linked-list is sorted in ascending order.
Merge all the linked-lists into one sorted linked-list and return it.
Time complexity: O(Nlogk) where k is the number of linked lists. Space complexit: A new linked list costs O(n) space; the priority queue costs O(k) space.
public ListNode mergeKLists(ListNode[] lists) {
ListNode preHead = new ListNode(0);
Queue<ListNode> queue = new PriorityQueue<>((a, b) -> a.val - b.val);
for (ListNode node : lists) {
if (node != null) {
queue.offer(node);
}
}
ListNode point = preHead;
while (!queue.isEmpty()) {
ListNode node = queue.poll();
point.next = new ListNode(node.val);
point = point.next;
if (node.next != null) {
queue.offer(node.next);
}
}
return preHead.next;
}
Compute a Salary Cap
Design an algorithm for computing the salary cap, given existing salaries and the target payroll.
For example, if there were five employees with salaries last year were $90, $30, $100, $40, and $20, and the target payroll this year is $210, then $60 is a suitable salary cap, since 60+30+60+40+20=210.
This question is to calculate how much salary (cutoff) to pay the top employees to achieve the year’s target payroll.
public static double findSalaryCap(int[] currentSalaries, int targetPayroll) {
Arrays.sort(currentSalaries);
double unadjustedSalarySum = 0;
for (int i = 0; i < currentSalaries.length; i++) {
int adjustedPeople = currentSalaries.length - i;
double adjustedSalarySum = currentSalaries[i] * adjustedPeople;
if (unadjustedSalarySum + adjustedSalarySum >= targetPayroll) {
return (targetPayroll - unadjustedSalarySum) / adjustedPeople;
}
unadjustedSalarySum += currentSalaries[i];
}
return -1.0;
}
Searching
-
When we think of searching algorithms, we generally think of Binary Search: We look for an element x in a sorted array by first comparing x to the midpoint of the array. If x is less than the midpoint, then we search the left half of the array. If x is greater than the midpoint, then we search the right half of the array. We repeat this process, treating the left and right halves as subarrays until we either find x or the subarray has size 0.
-
The time complexity of binary search is O(log(n)), but a disadvantage of binary search is that it requires a sorted array and sorting an array takes O(nlog(n)) time. However if there are many searches to perform, the time taken to sort is not an issue. If your solution uses sorting, and the computation performed after sorting is faster than sorting, e.g., O(n) or O(log(n)), look for solutions that do not perform a complete sort.
-
To search an sorted array, use Arrays.binarySearch(A, “Tom”), the time complexity is O(log(n)); To search a sorted list-type object, use Collections.binarySearch(list, 42), the time complexity depends on the list item access way, it’s O(log(n)) for ArrayList, but O(n) for LinkedList (because we need to use fast-slow loop to find middle).
Binary Search Sample
Binary search can be written in many ways - recursive, iterative, different idioms for conditionals, etc.
public class BinarySearch {
public static int binarySearch(int[] a, int x) {
int low = 0;
int high = a.length - 1;
int mid;
while (low <= high) {
mid = low + (high - low) / 2; // avoid potential overflow!
if (a[mid] < x) {
low = mid + 1;
} else if (a[mid] > x) {
high = mid - 1;
} else {
return mid;
}
}
return -1;
}
public static int binarySearchRecursive(int[] a, int x, int low, int high) {
if (low > high)
return -1; // Error
int mid = low + (high - low) / 2;
if (a[mid] < x) {
return binarySearchRecursive(a, x, mid + 1, high);
} else if (a[mid] > x) {
return binarySearchRecursive(a, x, low, mid - 1);
} else {
return mid;
}
}
// Recursive algorithm to return the closest element
public static int binarySearchRecursiveClosest(int[] a, int x, int low, int high) {
if (low > high) { // high is on the left side now
if (high < 0)
return low;
if (low >= a.length)
return high;
if (x - a[high] < a[low] - x) {
return high;
}
return low;
}
int mid = low + (high - low) / 2;
if (a[mid] < x) {
return binarySearchRecursiveClosest(a, x, mid + 1, high);
} else if (a[mid] > x) {
return binarySearchRecursiveClosest(a, x, low, mid - 1);
} else {
return mid;
}
}
public static void main(String[] args) {
int[] array = { 3, 6, 9, 12, 15, 18 };
for (int i = 0; i < 20; i++) {
int loc = binarySearch(array, i);
int loc2 = binarySearchRecursive(array, i, 0, array.length - 1);
int loc3 = binarySearchRecursiveClosest(array, i, 0, array.length - 1);
System.out.println(i + ": " + loc + " " + loc2 + " " + loc3);
}
}
Triple Binary Search
Given a contiguous sequence of numbers in which each number repeats thrice, there is exactly one missing number. Find the missing number.
eg: 11122333 : Missing number 2; 11122233344455666 Missing number 5
public static int tripleBinarySearch(int[] nums) {
int i = 0, j = nums.length - 1;
while (i < j - 1) { // skip loop if less than 3 nums
int mid = i + (j - i) / 2;
int inI = mid, inJ = mid;
while (inI >= 0 && nums[inI] == nums[mid])
inI--;
while (inJ < nums.length && nums[inJ] == nums[mid])
inJ++;
if (inJ - inI == 3) // 2 nums between
return nums[mid];
if (inI > 0 && (inI + 1) % 3 != 0)
j = inI;
else
i = inJ;
}
return nums[i];
}
Tries Searching
Achieve the following performance characteristics in typical applications:
- Search hits take time proportional to the length of the search key.
- Search misses involve examining only a few characters.
String-searching Algorithms
| algorithm (data structure) | search miss | memory usage | sweet spot |
|---|---|---|---|
| binary tree search (BST) | \(c_{1}(\lg n)^2\) | 64n | randomly ordered keys |
| 2-3 tree search (red-black BST) | \(c_{2}(\lg n)^2\) | 64n | guaranteed performance, logN key compares |
| linear probing (parallel arrays) | \(w\) | 32n to 128n | built-in types cached hash values, constant number of probes |
| trie search (R-way trie) | \(log_R n\) | (8R + 56)n to (8R + 56)wn | short keys, small alphabets, character-based operations |
| trie search (TST) | \(1.39\lg n\) | 64n to 64wn | nonrandom keys, character-based operations |
R-way Search Trees
Since the parameter R plays such a critical role, we refer to a trie for an R-character alphabet as an R-way trie. The R could be 26 (letters) or 256 (ASCII).
When you know that your keys are taken from a small alphabet, you can use Alphabet with toIndex() and toChar() method to convert indices between 0 and R - 1 to char values. So you can use only R links per node, at the cost of the time required to do the conversions between characters and indices.
Search time complexity O(n + 1), n is the key’s length. The average number of nodes examined for search miss in a trie built from n random keys over an alphabet of size R is \(~\log_R n\).
Search miss does not depend on the key length. with a 1 million random keys, will require examining only three or four nodes.
The number of links in a trie is between \(nR\) and \(wnR\), where w is the average key length. Decreasing R can save a huge amount of space. E.g. account number (02400019992993299111) has average length 20 and radix R = 10, build trie for 1 million keys, it will take 256 million space.
The bottom line is this: do not try to use this general trie for large numbers of long keys taken from large alphabets. instead, we can use Ternary Search Tries for this case.
public class TrieSET implements Iterable<String> {
private static final int R = 256; // extended ASCII
private Node root; // root of trie
private int n; // number of keys in trie
// R-way trie node
private static class Node {
private Node[] next = new Node[R];
private boolean isString;
}
/**
* Initializes an empty set of strings.
*/
public TrieSET() {
}
/**
* Does the set contain the given key?
*
* @param key
* the key
* @return {@code true} if the set contains {@code key} and {@code false} otherwise
* @throws IllegalArgumentException
* if {@code key} is {@code null}
*/
public boolean contains(String key) {
if (key == null)
throw new IllegalArgumentException("argument to contains() is null");
Node x = get(root, key, 0);
if (x == null)
return false;
return x.isString;
}
private Node get(Node x, String key, int d) {
if (x == null)
return null;
if (d == key.length())
return x;
char c = key.charAt(d);
return get(x.next[c], key, d + 1);
}
/**
* Adds the key to the set if it is not already present.
*
* @param key
* the key to add
* @throws IllegalArgumentException
* if {@code key} is {@code null}
*/
public void add(String key) {
if (key == null)
throw new IllegalArgumentException("argument to add() is null");
root = add(root, key, 0);
}
private Node add(Node x, String key, int d) {
if (x == null)
x = new Node();
if (d == key.length()) {
if (!x.isString)
n++;
x.isString = true;
} else {
char c = key.charAt(d);
x.next[c] = add(x.next[c], key, d + 1);
}
return x;
}
/**
* Returns the number of strings in the set.
*
* @return the number of strings in the set
*/
public int size() {
return n;
}
/**
* Is the set empty?
*
* @return {@code true} if the set is empty, and {@code false} otherwise
*/
public boolean isEmpty() {
return size() == 0;
}
/**
* Returns all of the keys in the set, as an iterator. To iterate over all of the keys in a set
* named {@code set}, use the foreach notation: {@code for (Key key : set)}.
*
* @return an iterator to all of the keys in the set
*/
public Iterator<String> iterator() {
return keysWithPrefix("").iterator();
}
/**
* Returns all of the keys in the set that start with {@code prefix}.
*
* @param prefix
* the prefix
* @return all of the keys in the set that start with {@code prefix}, as an iterable
*/
public Iterable<String> keysWithPrefix(String prefix) {
Queue<String> results = new LinkedList<String>();
Node x = get(root, prefix, 0);
collect(x, new StringBuilder(prefix), results);
return results;
}
private void collect(Node x, StringBuilder prefix, Queue<String> results) {
if (x == null)
return;
if (x.isString)
results.offer(prefix.toString());
for (char c = 0; c < R; c++) {
prefix.append(c);
collect(x.next[c], prefix, results);
prefix.deleteCharAt(prefix.length() - 1);
}
}
/**
* Returns all of the keys in the set that match {@code pattern}, where . symbol is treated as a
* wildcard character.
*
* @param pattern
* the pattern
* @return all of the keys in the set that match {@code pattern}, as an iterable, where . is
* treated as a wildcard character.
*/
public Iterable<String> keysThatMatch(String pattern) {
Queue<String> results = new LinkedList<String>();
StringBuilder prefix = new StringBuilder();
collect(root, prefix, pattern, results);
return results;
}
private void collect(Node x, StringBuilder prefix, String pattern, Queue<String> results) {
if (x == null)
return;
int d = prefix.length();
if (d == pattern.length() && x.isString)
results.offer(prefix.toString());
if (d == pattern.length())
return;
char c = pattern.charAt(d);
if (c == '.') {
for (char ch = 0; ch < R; ch++) {
prefix.append(ch);
collect(x.next[ch], prefix, pattern, results);
prefix.deleteCharAt(prefix.length() - 1);
}
} else {
prefix.append(c);
collect(x.next[c], prefix, pattern, results);
prefix.deleteCharAt(prefix.length() - 1);
}
}
/**
* Returns the string in the set that is the longest prefix of {@code query}, or {@code null},
* if no such string.
*
* @param query
* the query string
* @return the string in the set that is the longest prefix of {@code query}, or {@code null} if
* no such string
* @throws IllegalArgumentException
* if {@code query} is {@code null}
*/
public String longestPrefixOf(String query) {
if (query == null)
throw new IllegalArgumentException("argument to longestPrefixOf() is null");
int length = longestPrefixOf(root, query, 0, -1);
if (length == -1)
return null;
return query.substring(0, length);
}
// returns the length of the longest string key in the subtrie
// rooted at x that is a prefix of the query string,
// assuming the first d character match and we have already
// found a prefix match of length length
private int longestPrefixOf(Node x, String query, int d, int length) {
if (x == null)
return length;
if (x.isString)
length = d; // mark here!
if (d == query.length())
return length;
char c = query.charAt(d);
return longestPrefixOf(x.next[c], query, d + 1, length);
}
/**
* Removes the key from the set if the key is present.
*
* @param key
* the key
* @throws IllegalArgumentException
* if {@code key} is {@code null}
*/
public void delete(String key) {
if (key == null)
throw new IllegalArgumentException("argument to delete() is null");
root = delete(root, key, 0);
}
private Node delete(Node x, String key, int d) {
if (x == null)
return null;
if (d == key.length()) {
if (x.isString)
n--;
x.isString = false;
} else {
char c = key.charAt(d);
x.next[c] = delete(x.next[c], key, d + 1);
}
// remove subtrie rooted at x if it is completely empty
if (x.isString)
return x;
for (int c = 0; c < R; c++)
if (x.next[c] != null)
return x;
return null;
}
}
Ternary Search Tries
TSTs can help us avoid the excessive space cost associated with R-way tries. The number of links in a TST build from n string keys of average length w is between 3n and 3wn.
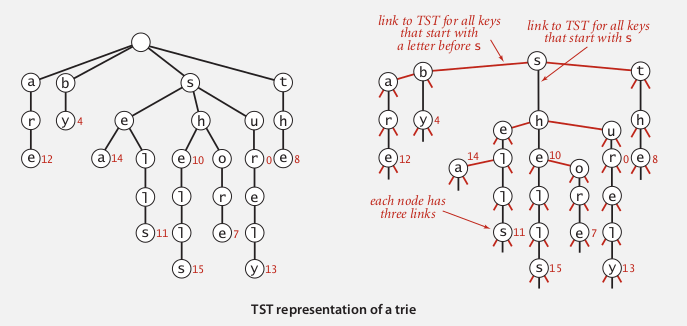
Comparing with Hashing, TSTs only examine just enough key characters, supports ordered symbol table operations, plus the character-based operations: Prefix Match, Wildcard Match, and Longest Prefix. Bottom line is TSTs are faster than Hashing and more flexible than Red-Blank BSTs.
T9 Text Input works by filtering the possibilities down sequentially starting with the first possible letters, So the first step in your example will be to filter the dictionary list to all words beginning with G, H, or I. Next step, take that list and filter the second letters by M, N, O. And so on…
4663 translates to {G,H,I}{M,N,O}{M,N,O}{D,E,F}
public class TST<Value> {
private int n; // size
private Node<Value> root; // root of TST
private static class Node<Value> {
private char c; // character
private Node<Value> left, mid, right; // left, middle, and right subtries
private Value val; // value associated with string
}
/**
* Initializes an empty string symbol table.
*/
public TST() {
}
/**
* Returns the number of key-value pairs in this symbol table.
*
* @return the number of key-value pairs in this symbol table
*/
public int size() {
return n;
}
/**
* Does this symbol table contain the given key?
*
* @param key
* the key
* @return {@code true} if this symbol table contains {@code key} and {@code false} otherwise
* @throws IllegalArgumentException
* if {@code key} is {@code null}
*/
public boolean contains(String key) {
if (key == null) {
throw new IllegalArgumentException("argument to contains() is null");
}
return get(key) != null;
}
/**
* Returns the value associated with the given key.
*
* @param key
* the key
* @return the value associated with the given key if the key is in the symbol table and
* {@code null} if the key is not in the symbol table
* @throws IllegalArgumentException
* if {@code key} is {@code null}
*/
public Value get(String key) {
if (key == null) {
throw new IllegalArgumentException("calls get() with null argument");
}
if (key.length() == 0)
throw new IllegalArgumentException("key must have length >= 1");
Node<Value> x = get(root, key, 0);
if (x == null)
return null;
return x.val;
}
// return subtrie corresponding to given key
private Node<Value> get(Node<Value> x, String key, int d) {
if (x == null)
return null;
if (key.length() == 0)
throw new IllegalArgumentException("key must have length >= 1");
char c = key.charAt(d);
if (c < x.c)
return get(x.left, key, d);
else if (c > x.c)
return get(x.right, key, d);
else if (d < key.length() - 1)
return get(x.mid, key, d + 1);
else
return x;
}
/**
* Inserts the key-value pair into the symbol table, overwriting the old value with the new
* value if the key is already in the symbol table. If the value is {@code null}, this
* effectively deletes the key from the symbol table.
*
* @param key
* the key
* @param val
* the value
* @throws IllegalArgumentException
* if {@code key} is {@code null}
*/
public void put(String key, Value val) {
if (key == null) {
throw new IllegalArgumentException("calls put() with null key");
}
if (!contains(key))
n++;
root = put(root, key, val, 0);
}
private Node<Value> put(Node<Value> x, String key, Value val, int d) {
char c = key.charAt(d);
if (x == null) {
x = new Node<Value>();
x.c = c;
}
if (c < x.c)
x.left = put(x.left, key, val, d);
else if (c > x.c)
x.right = put(x.right, key, val, d);
else if (d < key.length() - 1)
x.mid = put(x.mid, key, val, d + 1);
else
x.val = val;
return x;
}
/**
* Returns the string in the symbol table that is the longest prefix of {@code query}, or
* {@code null}, if no such string.
*
* @param query
* the query string
* @return the string in the symbol table that is the longest prefix of {@code query}, or
* {@code null} if no such string
* @throws IllegalArgumentException
* if {@code query} is {@code null}
*/
public String longestPrefixOf(String query) {
if (query == null) {
throw new IllegalArgumentException("calls longestPrefixOf() with null argument");
}
if (query.length() == 0)
return null;
int length = 0;
Node<Value> x = root;
int i = 0;
while (x != null && i < query.length()) {
char c = query.charAt(i);
if (c < x.c)
x = x.left;
else if (c > x.c)
x = x.right;
else {
i++;
if (x.val != null)
length = i;
x = x.mid;
}
}
return query.substring(0, length);
}
/**
* Returns all keys in the symbol table as an {@code Iterable}. To iterate over all of the keys
* in the symbol table named {@code st}, use the foreach notation:
* {@code for (Key key : st.keys())}.
*
* @return all keys in the symbol table as an {@code Iterable}
*/
public Iterable<String> keys() {
Queue<String> queue = new LinkedList<>();
;
collect(root, new StringBuilder(), queue);
return queue;
}
/**
* Returns all of the keys in the set that start with {@code prefix}.
*
* @param prefix
* the prefix
* @return all of the keys in the set that start with {@code prefix}, as an iterable
* @throws IllegalArgumentException
* if {@code prefix} is {@code null}
*/
public Iterable<String> keysWithPrefix(String prefix) {
if (prefix == null) {
throw new IllegalArgumentException("calls keysWithPrefix() with null argument");
}
Queue<String> queue = new LinkedList<>();
Node<Value> x = get(root, prefix, 0);
if (x == null)
return queue;
if (x.val != null)
queue.offer(prefix);
collect(x.mid, new StringBuilder(prefix), queue);
return queue;
}
// all keys in subtrie rooted at x with given prefix
private void collect(Node<Value> x, StringBuilder prefix, Queue<String> queue) {
if (x == null)
return;
collect(x.left, prefix, queue);
if (x.val != null)
queue.offer(prefix.toString() + x.c);
collect(x.mid, prefix.append(x.c), queue);
prefix.deleteCharAt(prefix.length() - 1);
collect(x.right, prefix, queue);
}
/**
* Returns all of the keys in the symbol table that match {@code pattern}, where . symbol is
* treated as a wildcard character.
*
* @param pattern
* the pattern
* @return all of the keys in the symbol table that match {@code pattern}, as an iterable, where
* . is treated as a wildcard character.
*/
public Iterable<String> keysThatMatch(String pattern) {
Queue<String> queue = new LinkedList<>();
collect(root, new StringBuilder(), 0, pattern, queue);
return queue;
}
private void collect(Node<Value> x, StringBuilder prefix, int i, String pattern, Queue<String> queue) {
if (x == null)
return;
char c = pattern.charAt(i);
if (c == '.' || c < x.c)
collect(x.left, prefix, i, pattern, queue);
if (c == '.' || c == x.c) {
if (i == pattern.length() - 1 && x.val != null)
queue.offer(prefix.toString() + x.c);
if (i < pattern.length() - 1) {
collect(x.mid, prefix.append(x.c), i + 1, pattern, queue);
prefix.deleteCharAt(prefix.length() - 1);
}
}
if (c == '.' || c > x.c)
collect(x.right, prefix, i, pattern, queue);
}
}
Implement Trie
Simple Version of Implementation
public class ImplementTrie {
private TrieNode root;
class TrieNode {
public char val;
public boolean isWord;
public TrieNode[] children = new TrieNode[26];
public TrieNode(char val) {
this.val = val;
}
}
/** Initialize your data structure here. */
public ImplementTrie() {
root = new TrieNode(' ');
}
/** Inserts a word into the trie. */
public void insert(String word) {
TrieNode node = root;
for (int i = 0; i < word.length(); i++) {
char c = word.charAt(i);
if (node.children[c - 'a'] == null) {
node.children[c - 'a'] = new TrieNode(c);
}
node = node.children[c - 'a'];
}
node.isWord = true;
}
/** Returns if the word is in the trie. */
public boolean search(String word) {
TrieNode node = root;
for (int i = 0; i < word.length(); i++) {
char c = word.charAt(i);
node = node.children[c - 'a'];
if (node == null)
return false;
}
return node.isWord;
}
/** Returns if there is any word in the trie that starts with the given prefix. */
public boolean startsWith(String prefix) {
TrieNode node = root;
for (int i = 0; i < prefix.length(); i++) {
char c = prefix.charAt(i);
node = node.children[c - 'a'];
if (node == null)
return false;
}
return true;
}
}
Word Search
/**
* <pre>
Given a 2D board and a word, find if the word exists in the grid.
The word can be constructed from letters of sequentially adjacent cell, where "adjacent" cells are those horizontally or vertically neighboring.
The same letter cell may not be used more than once.
For example,
Given board =
[
['A','B','C','E'],
['S','F','C','S'],
['A','D','E','E']
]
word = "ABCCED", -> returns true,
word = "SEE", -> returns true,
word = "ABCB", -> returns false.
* </pre>
*
*/
public boolean exist(char[][] board, String word) {
for (int row = 0; row < board.length; row++) {
for (int col = 0; col < board[row].length; col++) {
if (exist(board, row, col, word, 0))
return true;
}
}
return false;
}
private boolean exist(char[][] board, int row, int col, String word, int start) {
if (start == word.length())
return true;
if (row < 0 || row >= board.length || col < 0 || col >= board[row].length)
return false;
if (board[row][col] != word.charAt(start))
return false;
board[row][col] = '#';
boolean exist = exist(board, row + 1, col, word, start + 1) || exist(board, row, col + 1, word, start + 1)
|| exist(board, row - 1, col, word, start + 1) || exist(board, row, col - 1, word, start + 1);
board[row][col] = word.charAt(start);
return exist;
}
/**
* <pre>
Given a 2D board and a list of words from the dictionary, find all words in the board.
Each word must be constructed from letters of sequentially adjacent cell, where "adjacent" cells are those horizontally or vertically neighboring.
The same letter cell may not be used more than once in a word.
For example,
Given words = ["oath","pea","eat","rain"] and board =
[
['o','a','a','n'],
['e','t','a','e'],
['i','h','k','r'],
['i','f','l','v']
]
Return ["eat","oath"].
* </pre>
*
* Solution:
*
* Backtracking with Trie, also Gradually prune the nodes in Trie during the backtracking.
*
* Time complexity: O(M(4⋅3^(L−1))) where M is the number of cells in the board and L is the maximum
* length of words.
*
* Space Complexity: O(N), where N is the total number of letters in the dictionary.
*
*/
public List<String> findWords(char[][] board, String[] words) {
List<String> result = new ArrayList<>();
Node trie = buildTrie(words);
for (int row = 0; row < board.length; row++) {
for (int col = 0; col < board[row].length; col++) {
backtrack(board, row, col, trie, result);
}
}
return result;
}
private void backtrack(char[][] board, int row, int col, Node node, List<String> result) {
char c = board[row][col];
if (c == '#' || node.next[c - 'a'] == null)
return;
node = node.next[c - 'a'];
if (node.word != null) {
result.add(node.word);
node.word = null; // Avoid duplicate
// Gradually prune up all leaves in Trie during the backtracking.
Node n = node;
while (n.count == 0 && n.parent != null) {
n.parent.next[n.chr - 'a'] = null;
n.parent.count--;
n = n.parent;
}
}
board[row][col] = '#';
if (row > 0)
backtrack(board, row - 1, col, node, result);
if (col > 0)
backtrack(board, row, col - 1, node, result);
if (row < board.length - 1)
backtrack(board, row + 1, col, node, result);
if (col < board[0].length - 1)
backtrack(board, row, col + 1, node, result);
board[row][col] = c;
}
private Node buildTrie(String[] words) {
Node root = new Node((char) 0, null);
for (String word : words) {
Node node = root;
for (char c : word.toCharArray()) {
int i = c - 'a';
if (node.next[i] == null) {
node.next[i] = new Node(c, node);
node.count++;
}
node = node.next[i];
}
node.word = word;
}
return root;
}
class Node {
char chr;
Node parent;
Node[] next = new Node[26];
int count = 0; // Count children nodes, zero means a leave
String word = null;
public Node(char chr, Node parent) {
this.chr = chr;
this.parent = parent;
}
}
Unique Word Abbreviation
/**
* <pre>
A string such as "word" contains the following abbreviations:
["word", "1ord", "w1rd", "wo1d", "wor1", "2rd", "w2d", "wo2", "1o1d", "1or1", "w1r1", "1o2", "2r1", "3d", "w3", "4"]
Given a target string and a set of strings in a dictionary, find an abbreviation of this target string with the smallest possible length such that it does not conflict with abbreviations of the strings in the dictionary.
Each number or letter in the abbreviation is considered length = 1. For example, the abbreviation "a32bc" has length = 4.
Note:
In the case of multiple answers as shown in the second example below, you may return any one of them.
Assume length of target string = m, and dictionary size = n. You may assume that m ≤ 21, n ≤ 1000, and log2(n) + m ≤ 20.
Examples:
"apple", ["blade"] -> "a4" (because "5" or "4e" conflicts with "blade")
"apple", ["plain", "amber", "blade"] -> "1p3" (other valid answers include "ap3", "a3e", "2p2", "3le", "3l1").
*
* </pre>
*
* @author lchen
* @category Hard
*
*/
public class MinimumUniqueWordAbbreviation {
public String minAbbreviation(String target, String[] dictionary) {
List<String> dict = new ArrayList<>();
int len = target.length();
for (String str : dictionary)
if (str.length() == len)
dict.add(str);
if (dict.isEmpty())
return "" + len;
Node root = new Node();
for (String str : dict)
root.add(str);
char[] cc = target.toCharArray();
String ret = null;
int min = 1, max = len;
while (max >= min) {
int mid = min + ((max - min) / 2);
List<String> abbs = new ArrayList<>();
getAbbs(cc, 0, mid, new StringBuilder(), abbs);
boolean conflict = true;
for (String abbr : abbs) {
if (!root.isAbbr(abbr, 0)) {
conflict = false;
ret = abbr;
break;
}
}
if (conflict) {
min = mid + 1;
} else {
max = mid - 1;
}
}
return ret;
}
void getAbbs(char[] cc, int s, int len, StringBuilder sb, List<String> abbs) { // DFS with backtracking
boolean preNum = (sb.length() > 0) && (sb.charAt(sb.length() - 1) >= '0') && (sb.charAt(sb.length() - 1) <= '9');
if (len == 1) {
if (s < cc.length) {
if (s == cc.length - 1)
abbs.add(sb.toString() + cc[s]); // add one char
if (!preNum)
abbs.add(sb.toString() + (cc.length - s)); // add a number
}
} else if (len > 1) {
int last = sb.length();
for (int i = s + 1; i < cc.length; i++) {
if (!preNum) { // add a number
sb.append(i - s);
getAbbs(cc, i, len - 1, sb, abbs);
sb.delete(last, sb.length());
}
if (i == s + 1) { // add one char
sb.append(cc[s]);
getAbbs(cc, i, len - 1, sb, abbs);
sb.delete(last, sb.length());
}
}
}
}
class Node { // Trie Node
Node[] nodes;
boolean isWord;
Node() {
nodes = new Node[26];
isWord = false;
}
void add(String str) { // add a word to Trie
if (str.length() == 0)
isWord = true; // end of a word
else {
int idx = str.charAt(0) - 'a'; // insert a new node
if (nodes[idx] == null)
nodes[idx] = new Node();
nodes[idx].add(str.substring(1));
}
}
boolean isAbbr(String abbr, int num) {
if (num > 0) { // number of '*'
for (Node node : nodes) {
if (node != null && node.isAbbr(abbr, num - 1))
return true;
}
return false; // not exist in the dictionary
} else {
if (abbr.length() == 0)
return isWord; // at the end of the addr
int idx = 0; // get the number of '*' at the start of the abbr
while (idx < abbr.length() && abbr.charAt(idx) >= '0' && abbr.charAt(idx) <= '9') {
num = (num * 10) + (abbr.charAt(idx++) - '0');
}
if (num > 0)
return isAbbr(abbr.substring(idx), num); // start with number
else { // start with non-number
if (nodes[abbr.charAt(0) - 'a'] != null)
return nodes[abbr.charAt(0) - 'a'].isAbbr(abbr.substring(1), 0);
else
return false; // not exist in the dictionary
}
}
}
}
Searching Boot Camp
Search For First Occurrence
Write a method that takes a sorted array and a key and returns the index of the first occurrence of that key in the array.
public int searchForFirstOccurance(List<Integer> A, int k) {
int left = 0, right = A.size() - 1, result = -1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (A.get(mid) > k) {
right = mid - 1;
} else if (A.get(mid) == k) {
result = mid;
// nothing to the right of mid can be the first occurrence of k
right = mid - 1;
} else {
left = mid + 1;
}
}
return result;
}
First and Last Position in Sorted Array
Given an array of integers nums sorted in ascending order, find the starting and ending position of a given target value.
Your algorithm’s runtime complexity must be in the order of O(log n).
If the target is not found in the array, return [-1, -1].
Example 1:
Input: nums = [5,7,7,8,8,10], target = 8
Output: [3,4]
public int[] searchRange(int[] nums, int target) {
int start = firstGreaterEqual(nums, target);
if (start == nums.length || nums[start] > target) {
return new int[] { -1, -1 };
}
return new int[] { start, firstGreaterEqual(nums, target + 1) - 1 };
}
private int firstGreaterEqual(int[] nums, int target) {
int low = 0, high = nums.length;
while (low < high) {
int mid = low + ((high - low) >> 1);
// find first greater than equal
if (nums[mid] < target) {
low = mid + 1;
} else {
high = mid;
}
}
return low;
}
public int[] searchRange2(int[] nums, int target) {
int leftIdx = extremeInsertionIndex(nums, target, true);
// Check `leftIdx` is within the array bounds and that `target` is actually in `nums`.
if (leftIdx == nums.length || nums[leftIdx] != target) {
return new int[] { -1, -1 };
}
return new int[] { leftIdx, extremeInsertionIndex(nums, target, false) - 1 };
}
// returns leftmost (or rightmost) index at which `target` should be
// inserted in sorted array `nums` via binary search.
private int extremeInsertionIndex(int[] nums, int target, boolean left) {
int low = 0;
int high = nums.length;
while (low < high) {
int mid = (low + high) / 2;
if (nums[mid] > target || (left && target == nums[mid])) {
high = mid;
} else {
low = mid + 1;
}
}
return low;
}
Search In Rotated Sorted Array
Suppose an array sorted in ascending order is rotated at some pivot unknown to you beforehand.
(i.e., 0 1 2 4 5 6 7 might become 4 5 6 7 0 1 2).
You are given a target value to search. If found in the array return its index, otherwise return -1.
You may assume no duplicate exists in the array.
What if duplicates are allowed?
public int searchInRotatedSortedArray(int[] nums, int target) {
int start = 0;
int end = nums.length - 1;
while (start <= end) {
int mid = start + (end - start) / 2;
if (nums[mid] == target)
return mid;
if (nums[start] <= nums[mid]) { // left side sorted
if (target < nums[mid] && target >= nums[start]) // target in left side
end = mid - 1;
else
start = mid + 1;
} else { // right side sorted
if (target > nums[mid] && target <= nums[end]) // target in right side
start = mid + 1;
else
end = mid - 1;
}
}
return -1;
}
// if has duplicates, like nums = [1, 3, 1, 1, 1]; target = 3
// worest case O(n), otherwise O(log(n))
public boolean searchInRotatedSortedArray2(int[] nums, int target) {
int start = 0;
int end = nums.length - 1;
while (start <= end) {
int mid = start + (end - start) / 2;
if (nums[mid] == target)
return true;
// exceptional case due to duplicates
if (nums[start] == nums[mid] && nums[mid] == nums[end]) {
end--; // break the tie
} else if (nums[start] <= nums[mid]) {
if (target < nums[mid] && target >= nums[start])
end = mid - 1;
else
start = mid + 1;
} else {
if (target > nums[mid] && target <= nums[end])
start = mid + 1;
else
end = mid - 1;
}
}
return false;
}
Compute The Largest Square Root
Also resolve the question: Valid Perfect Square
Write a program which takes a nonnegative integer and returns the largest integer whose square is less than or equal to the given integer. For example, if the input is 16, return 4; if the input is 300, return 17, since 17^2 = 289 < 300.
Use binary search to achieve the complexity log2(n).
public int computeSquareRootInt(int k) {
long left = 0, right = k;
while (left <= right) {
long mid = left + (right - left) / 2;
long midSquare = mid * mid;
if (midSquare <= k)
left = mid + 1;
else
right = mid - 1;
}
return (int) left - 1;
}
Search a 2D Matrix II
Search in a sorted 2D Matrix
Write an efficient algorithm that searches for a value in an m x n matrix. This matrix has the following properties:
Integers in each row are sorted in ascending from left to right.
Integers in each column are sorted in ascending from top to bottom.
For example,
Consider the following matrix:
[ [1, 4, 7, 11, 15], [2, 5, 8, 12, 19], [3, 6, 9, 16, 22], [10, 13, 14, 17, 24], [18, 21, 23, 26, 30] ]
Given target = 5, return true.
Given target = 20, return false.
We start searching the matrix from top right corner, if the target is greater than the value in current position, then the target can not be in entire row of current position because the row is sorted; if the target is less than the value in current position, then the target can not in the entire column because the column is sorted too. We can rule out one row or one column each time, so the time complexity is O(m+n).
public boolean searchIn2DSortedMatrix(int[][] matrix, int target) {
if (matrix == null || matrix.length < 1 || matrix[0].length < 1)
return false;
int row = 0;
int col = matrix[0].length - 1;
while (row < matrix.length && col >= 0) {
if (target == matrix[row][col])
return true;
else if (target < matrix[row][col])
col--;
else
row++;
}
return false;
}
Kth Smallest Element in Sorted Matrix
Given a n x n matrix where each of the rows and columns are sorted in ascending order, find the kth smallest element in the matrix.
Note that it is the kth smallest element in the sorted order, not the kth distinct element.
Example:
matrix = [
[ 1, 5, 9],
[10, 11, 13],
[12, 13, 15]
],
k = 8,
return 13.
This sorted matrix is partially sorted, so to get the kth smallest element (which should be linear sorted), we need to do the rest of sorting work to solved it. There are 2 ways to do it: use a min heap (priority queue) or binary search. Based on the nature of this matrix, move forward to next potential candidates.
// Use min heap
public int kthSmallest(int[][] matrix, int k) {
int m = matrix.length, n = matrix[0].length;
Queue<Node> queue = new PriorityQueue<Node>();
for (int c = 0; c <= n - 1; c++)
queue.offer(new Node(0, c, matrix[0][c]));
for (int i = 0; i < k - 1; i++) {
Node node = queue.poll();
if (node.x == m - 1)
continue;
queue.offer(new Node(node.x + 1, node.y, matrix[node.x + 1][node.y]));
}
return queue.poll().val;
}
class Node implements Comparable<Node> {
int x, y, val;
public Node(int x, int y, int val) {
this.x = x;
this.y = y;
this.val = val;
}
@Override
public int compareTo(Node that) {
return this.val - that.val;
}
}
// Simulate Binary Search
public int kthSmallest2(int[][] matrix, int k) {
int m = matrix.length, n = matrix[0].length;
int lo = matrix[0][0], hi = matrix[m - 1][n - 1];
while (lo < hi) {
int mid = lo + (hi - lo) / 2;
int count = 0, j = n - 1;
for (int i = 0; i < m; i++) {
while (j >= 0 && matrix[i][j] > mid)
j--;
count += j + 1;
}
if (count < k)
lo = mid + 1;
else
hi = mid;
}
return lo;
}
This is also a similar question as “Find K Pairs with Smallest Sums”.
Given 2 sorted arrays.
For example:
Given nums1 = [1,7,11], nums2 = [2,4,6], k = 3
Return: [1,2],[1,4],[1,6]
The first 3 pairs are returned from the sequence:
[1,2],[1,4],[1,6],[7,2],[7,4],[11,2],[7,6],[11,4],[11,6]
public List<int[]> kSmallestPairs(int[] nums1, int[] nums2, int k) {
int m = nums1.length, n = nums2.length;
List<int[]> result = new ArrayList<>();
if (m == 0 || n == 0 || k <= 0)
return result;
Queue<Node> queue = new PriorityQueue<>();
for (int i = 0; i < n; i++) {
queue.offer(new Node(0, i, nums1[0] + nums2[i]));
}
for (int i = 0; i < Math.min(k, m * n); i++) {
Node node = queue.poll();
result.add(new int[] { nums1[node.x], nums2[node.y] });
if (node.x == m - 1)
continue;
queue.offer(new Node(node.x + 1, node.y, nums1[node.x + 1] + nums2[node.y]));
}
return result;
}
Kth Smallest Prime Fraction
A sorted list A contains 1, plus some number of primes. Then, for every p < q in the list, we consider the fraction p/q.
What is the K-th smallest fraction considered? Return your answer as an array of ints, where answer[0] = p and answer[1] = q.
Examples:
Input: A = [1, 2, 3, 5], K = 3
Output: [2, 5]
Explanation:
The fractions to be considered in sorted order are:
1/5, 1/3, 2/5, 1/2, 3/5, 2/3.
The third fraction is 2/5.
Input: A = [1, 7], K = 1
Output: [1, 7]
We’ll maintain a heap of potential fractions - the smallest unused fractions with denominator primes[j]. We’ll pop K-1 elements from this heap, then the final fraction will be the answer. Time Complexity: O(KlogN), where N is the length of A. The heap has up to N elements.
public int[] kthSmallestPrimeFraction(int[] A, int K) {
PriorityQueue<int[]> pq = new PriorityQueue<int[]>((a, b) -> A[a[0]] * A[b[1]] - A[a[1]] * A[b[0]]);
for (int i = 1; i < A.length; ++i)
pq.add(new int[] { 0, i });
while (--K > 0) {
int[] frac = pq.poll();
if (frac[0]++ < frac[1])
pq.offer(frac);
}
int[] ans = pq.poll();
return new int[] { A[ans[0]], A[ans[1]] };
}
Find Kth Smallest Pair Distance
Given an integer array, return the k-th smallest distance among all the pairs. The distance of a pair (A, B) is defined as the absolute difference between A and B.
Example 1:
Input:
nums = [1,3,1]
k = 1
Output: 0
Explanation:
Here are all the pairs:
(1,3) -> 2
(1,1) -> 0
(3,1) -> 2
Then the 1st smallest distance pair is (1,1), and its distance is 0.
Solution: We will use a sliding window approach to count the number of pairs with distance <= guess.
For every possible right, we maintain the loop invariant: left is the smallest value such that nums[right] - nums[left] <= guess. Then, the number of pairs with right as it’s right-most endpoint is right - left, and we add all of these up.
Time Complexity: O(NlogW+NlogN), where N is the length of nums, and W is equal to nums[nums.length - 1] - nums[0]. The logW factor comes from our binary search, and we do O(N) work inside our call to possible (or to calculate count in Java). The final O(NlogN) factor comes from sorting.
public int smallestDistancePair(int[] nums, int k) {
Arrays.sort(nums);
int lo = 0;
int hi = nums[nums.length - 1] - nums[0];
while (lo < hi) {
int mi = (lo + hi) / 2;
int count = 0, left = 0;
for (int right = 0; right < nums.length; right++) {
while (nums[right] - nums[left] > mi)
left++;
count += right - left;
}
// count = number of pairs with distance <= mi
if (count >= k)
hi = mi;
else
lo = mi + 1;
}
return lo;
}
Find The Min and Max Streamly
Design an algorithm to find the min and max elements in an array. For example, if A = [3, 2, 5, 1, 2, 4], you should return 1 for the min and 5 for the max.
One way of think of this problem is that we are searching for the strongest and weakest players in a group of players. There is no point in looking at any player who won a game when we want to find the weakest player. The better approach is to play n/2 matches between disjoint pairs of players. The strongest player will come from the n/2 winners and the weakest player will come from the n/2 losers.
Once we implement it in streaming fashion, by maintaining candidate min and max as we process successive pairs. we can achieve the time complexity O(n) and the space complexity O(1).
public static MinMax findMinMax(List<Integer> A) {
if (A.size() == 1)
return new MinMax(A.get(0), A.get(0));
MinMax globalMinMax = MinMax.minMax(A.get(0), A.get(1));
// Process two elements at a time.
for (int i = 2; i < A.size() - 1; i += 2) {
MinMax localMinMax = MinMax.minMax(A.get(i), A.get(i + 1));
globalMinMax = new MinMax(Math.min(globalMinMax.smallest, localMinMax.smallest),
Math.max(globalMinMax.largest, localMinMax.largest));
}
// If there is odd number of elements in the array, we still
// need to compare the last element with the existing answer.
if ((A.size() % 2) != 0) {
globalMinMax = new MinMax(Math.min(globalMinMax.smallest, A.get(A.size() - 1)),
Math.max(globalMinMax.largest, A.get(A.size() - 1)));
}
return globalMinMax;
}
private static class MinMax {
public Integer smallest;
public Integer largest;
public MinMax(Integer smallest, Integer largest) {
this.smallest = smallest;
this.largest = largest;
}
private static MinMax minMax(Integer a, Integer b) {
return Integer.compare(b, a) < 0 ? new MinMax(b, a) : new MinMax(a, b);
}
}
Find The Kth Largest Element
Find the kth largest element in an unsorted array. Note that it is the kth largest element in the sorted order, not the kth distinct element.
For example, Given [3,2,1,5,6,4] and k = 2, return 5.
The average time complexity T(n) satisfies T(n) = O(n) + T(n/2). This solves to T(n) = O(n). The space complexity is O(1) as we are using the array itself to record the partition.
private int findKthLargest(int[] nums, int start, int end, int k) {
if (start > end)
return Integer.MAX_VALUE;
int left = start;
int pivot = nums[end];
for (int i = start; i <= end; i++) {
if (nums[i] > pivot) // Kth Largest!
swap(nums, left++, i);
}
swap(nums, left, end);
if (left == k - 1)
return nums[left];
else if (left < k - 1)
return findKthLargest(nums, left + 1, end, k);
else
return findKthLargest(nums, start, left - 1, k);
}
private void swap(int[] nums, int i, int j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
Find The Missing IP Address
Suppose you were given a file containing roughly one billion IP addresses, each of which is a 32-bit quantity. How would you programmatically find an IP address that is not in the file? Assume you have unlimited drive space but only a few megabytes of RAM at your disposal.
Since we have more storage, we can count on groups of bits. Specifically, we can count the number of IP addresses in the file that begin with 0, 1, 2, …, 2^16 - 1 using an array of 2^16 integers that can be represented with 32 bits. For every IP address in the file, we take its 16 MSBs to index into this array and increment the count of that number. Since the file contains fewer than 2^32 numbers, there must be one entry in the array that is less than 2^16. This tells us that there is at lease one IP address which has those upper bits and is not in the file. In the second pass, we can focus only on the addresses whose leading 16 bits match the one we have found, and use a bit array of size 2^16 to identify a missing address.
The storage requirements is dominated by the count array, i.e., 2^16 (array size) * 4 (4 bytes int) / 1024 / 1024 = 0.25MB
public static int findMissingIPAddress(Iterable<Integer> sequence) {
final int NUM_BUCKET = 1 << 16;
int[] counter = new int[NUM_BUCKET];
Iterator<Integer> s = sequence.iterator();
while (s.hasNext()) {
int idx = s.next() >>> 16;
++counter[idx];
}
for (int i = 0; i < counter.length; ++i) {
// Look for a bucket that contains less than NUM_BUCKET elements.
if (counter[i] < NUM_BUCKET) {
BitSet bitSet = new BitSet(NUM_BUCKET);
s = sequence.iterator(); // Search from the beginning again.
while (s.hasNext()) {
int x = s.next();
if (i == (x >>> 16)) {
bitSet.set(x & (NUM_BUCKET - 1)); // Gets the lower 16 bits of x.
}
}
for (int j = 0; j < NUM_BUCKET; ++j) {
if (!bitSet.get(j)) {
return (i << 16) | j;
}
}
}
}
throw new IllegalArgumentException("no missing ip address.");
}
Find Duplicate and Missing Elements
You are given an array of n integers, each between 0 and n - 1, inclusive. Exactly one element appears twice, implying that exactly one number between 0 and n - 1 is missing from the array. How would you compute the duplicate and missing numbers?
Consider performing multiple passes through the array with XOR operations. You might know the fact that the sum of the numbers from 0 to n - 1, inclusive, is (n-1)*n/2, so the sum of the elements in the array is exactly (n-1)*n/2 + (t-m), let the t is num appears twice and m is the missing one. But we need one more equation to solve it. The following solution takes advantage of XOR.
The time complexity is O(n) and the space complexity is O(1).
public int[] findDuplicateMissingNumber(int[] A) {
// Compute the XOR of all numbers from 0 to |A| - 1 and all entries in A.
// This will yield the missing number XOR the duplicate number (t xor m)
int missXorDup = 0;
for (int i = 0; i < A.length; i++) {
missXorDup ^= i ^ A[i];
}
// The bit-fiddling assignment below sets all of bits in differBit to 0 except for the least
// significant bit in missXorDup that's 1.
int differBit = missXorDup & (~(missXorDup - 1)); // e.g. 10000...
// Now we can focus our attention on entries where the LSB is 1.
// Compute the XOR of all numbers in which the differBit-th bit is 1.
// The result is either the missing or the duplicate entry.
// Put it another way, it's to split the entries to 2 groups by comparing with differBit
int missOrDup = 0;
for (int i = 0; i < A.length; i++) {
if ((i & differBit) != 0)
missOrDup ^= i; // xor to filter out duplicates
if ((A[i] & differBit) != 0)
missOrDup ^= A[i]; // xor to filter out duplicates
}
// missOrDup is either the missing value or the duplicated entry.
for (int a : A) {
if (a == missOrDup)
return new int[] { missOrDup, missOrDup ^ missXorDup };
}
return new int[] { missOrDup ^ missXorDup, missOrDup };
}
Balanced Split
Given a set of integers (which may include repeated integers), determine if there’s a way to split the set into two subsets A and B such that the sum of the integers in both sets is the same, and all of the integers in A are strictly smaller than all of the integers in B. Note: Strictly smaller denotes that every integer in A must be less than, and not equal to, every integer in B.
Example: nums = [1, 5, 7, 1], output = true, We can split the set into A = {1, 1, 5} and B = {7}.
public class BalancedSplit {
public boolean balancedSplit(int[] nums) {
if (nums == null || nums.length == 0)
return true;
long sum = 0;
for (int num : nums) {
sum += num;
}
if (sum % 2 == 1) {
return false; // odd sum, impossible split
}
return canSplit(nums, sum / 2, 0, 0, nums.length - 1);
}
private boolean canSplit(int[] nums, long target, long leftSum, int left, int right) {
if (left >= right) {
return false;
}
int lastLeft = left, lastRight = right;
int pivot = nums[left + (right - left) / 2];
long sum = 0;
while (left < right) {
// add pivot to the left sub array!
while (left < nums.length && nums[left] <= pivot) {
sum += nums[left];
left++;
}
while (nums[right] > pivot) {
right--;
}
if (left < right) {
int temp = nums[left];
nums[left] = nums[right];
nums[right] = temp;
sum += nums[left];
left++;
right--;
}
}
sum += leftSum; // add left sum from last time
if (sum == target) {
return true;
} else if (sum < target) {
// the split point should be on the right side
return canSplit(nums, target, sum, left, lastRight);
} else {
if (lastRight == right) {
return false; // break the cycle
}
// the split point should be on the left side
return canSplit(nums, target, leftSum, lastLeft, right);
}
}
public static void main(String[] args) {
BalancedSplit solution = new BalancedSplit();
Assert.assertTrue(solution.balancedSplit(new int[] { 1, 5, 7, 1 }));
Assert.assertFalse(solution.balancedSplit(new int[] { 12, 7, 6, 7, 6 }));
Assert.assertTrue(solution.balancedSplit(new int[] {}));
Assert.assertFalse(solution.balancedSplit(new int[] { 2 }));
Assert.assertFalse(solution.balancedSplit(new int[] { 20, 2 }));
Assert.assertTrue(solution.balancedSplit(new int[] { 5, 7, 20, 12, 5, 7, 6, 14, 5, 5, 6 }));
Assert.assertFalse(solution.balancedSplit(new int[] { 5, 7, 20, 12, 5, 7, 6, 7, 14, 5, 5, 6 }));
Assert.assertFalse(solution.balancedSplit(new int[] { 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }));
Assert.assertTrue(solution.balancedSplit(new int[] { 0, 0, 0 }));
}
}
K Closest Points to Origin
Given an array of points where points[i] = [xi, yi] represents a point on the X-Y plane and an integer k, return the k closest points to the origin (0, 0).
The distance between two points on the X-Y plane is the Euclidean distance.
You may return the answer in any order. The answer is guaranteed to be unique (except for the order that it is in).
https://leetcode.com/problems/k-closest-points-to-origin/
public int[][] kClosest(int[][] points, int k) {
int left = 0, right = points.length - 1;
int pivotIndex = points.length;
while (pivotIndex != k) {
pivotIndex = partition(points, left, right);
if (pivotIndex < k) {
left = pivotIndex;
} else {
right = pivotIndex - 1;
}
}
return Arrays.copyOf(points, k);
}
private int partition(int[][] points, int left, int right) {
int[] pivot = points[left + (right - left) / 2];
int pivotDist = squaredDistance(pivot);
// equals can make sure the left pointer just past the end of left range
while (left <= right) {
while (squaredDistance(points[left]) < pivotDist) {
left++;
}
while (squaredDistance(points[right]) > pivotDist) {
right--;
}
if (left <= right) {
int[] temp = points[left];
points[left] = points[right];
points[right] = temp;
left++;
right--;
}
}
return left;
}
private int squaredDistance(int[] point) {
return point[0] * point[0] + point[1] * point[1];
}
Find An Element Appears Once
Given an integer array, in which each entry but one appears in triplicate, find the element appearing once. For example, if the array is {2, 4, 2, 5, 2, 5, 5}, you should return 4.
Solution:
Count the number of 1s at each bit for all elements. And mod 3 to cast out the contributions of elements that appear exactly three times.
public int findElementAppearsOnce(int[] nums) {
int[] counts = new int[32];
for (int num : nums) {
for (int i = 0; i < 32; i++) {
counts[i] += num & 1;
num >>= 1; // or num &= (num - 1)
}
}
int result = 0;
for (int i = 0; i < 32; i++) {
result |= (counts[i] % 3) << i;
}
return result;
}
Sell Diminishing-Valued Colored Balls
/**
* Sell Diminishing-Valued Colored Balls
*
* https://leetcode.com/problems/sell-diminishing-valued-colored-balls/
*/
public class SellDiminishingValuedColoredBalls {
public int maxProfit(int[] inventory, int orders) {
int lo = 0, hi = Arrays.stream(inventory).max().getAsInt();
while (lo < hi) {
int mid = lo + (hi - lo) / 2;
if (getBallCnt(inventory, mid, orders) > orders) {
lo = mid + 1;
} else {
hi = mid;
}
}
int remainMax = lo;
long result = 0L;
for (int cnt : inventory) {
if (cnt <= remainMax)
continue;
result += (long) (cnt + remainMax + 1) * (long) (cnt - remainMax) / 2;
orders -= cnt - remainMax;
}
result += (long) remainMax * (long) orders;
return (int) (result % (long) (1e9 + 7));
}
private int getBallCnt(int[] inventory, int remainMax, int total) {
int res = 0;
for (int cnt : inventory) {
if (cnt <= remainMax)
continue;
res += (cnt - remainMax);
if (res > total)
break;
}
return res;
}
}
Capacity To Ship Packages Within D Days
A conveyor belt has packages that must be shipped from one port to another within days days.
The ith package on the conveyor belt has a weight of weights[i]. Each day, we load the ship with packages on the conveyor belt (in the order given by weights). We may not load more weight than the maximum weight capacity of the ship.
Return the least weight capacity of the ship that will result in all the packages on the conveyor belt being shipped within days days.
Example 2: Input: weights = [3,2,2,4,1,4], days = 3 Output: 6 Explanation: A ship capacity of 6 is the minimum to ship all the packages in 3 days like this: 1st day: 3, 2 2nd day: 2, 4 3rd day: 1, 4
public int shipWithinDays(int[] weights, int days) {
int low = 0, high = 0;
for (int weight : weights) {
low = Math.max(low, weight);
}
high = (int) Math.ceil((double) weights.length / days) * low;
while (low <= high) {
int mid = low + (high - low) / 2;
if (isPossible(weights, days, mid)) {
high = mid - 1;
} else {
low = mid + 1;
}
}
return low;
}
public boolean isPossible(int[] weights, int days, int capacity) {
int weightSum = 0;
int daysCount = 0;
for (int weight : weights) {
if (weightSum + weight <= capacity) {
weightSum += weight;
} else {
daysCount++;
weightSum = weight;
if (daysCount >= days || weight > capacity) {
return false;
}
}
}
return true;
}